 这一周集中体验了PandaAI的智能体功能,从最基础的节点拖拽开始,到搭建多智能体协作的工作流,再到思考RAG数据污染的防护问题,一路走下来有收获也有困惑。社区里有不少用户分享了类似的经历,这篇心得主要围绕两个我之前比较关心的问题:新功能怎么跟旧功能结合起来用,以及RAG带来的数据污染风险到底怎么防。如果你也在入门阶段,希望能给你一点参考。
这一周集中体验了PandaAI的智能体功能,从最基础的节点拖拽开始,到搭建多智能体协作的工作流,再到思考RAG数据污染的防护问题,一路走下来有收获也有困惑。社区里有不少用户分享了类似的经历,这篇心得主要围绕两个我之前比较关心的问题:新功能怎么跟旧功能结合起来用,以及RAG带来的数据污染风险到底怎么防。如果你也在入门阶段,希望能给你一点参考。
一、智能体功能整合:从“不会用”到“勉强会用”
- 第一印象:这不是我想象中的“聊天机器人”
当前 panda ai的 工作流是对论文代码的极致简化,

不同于原有代码复杂的框架,可以说当前 panda ai的 工作流是对论文代码的极致简化,
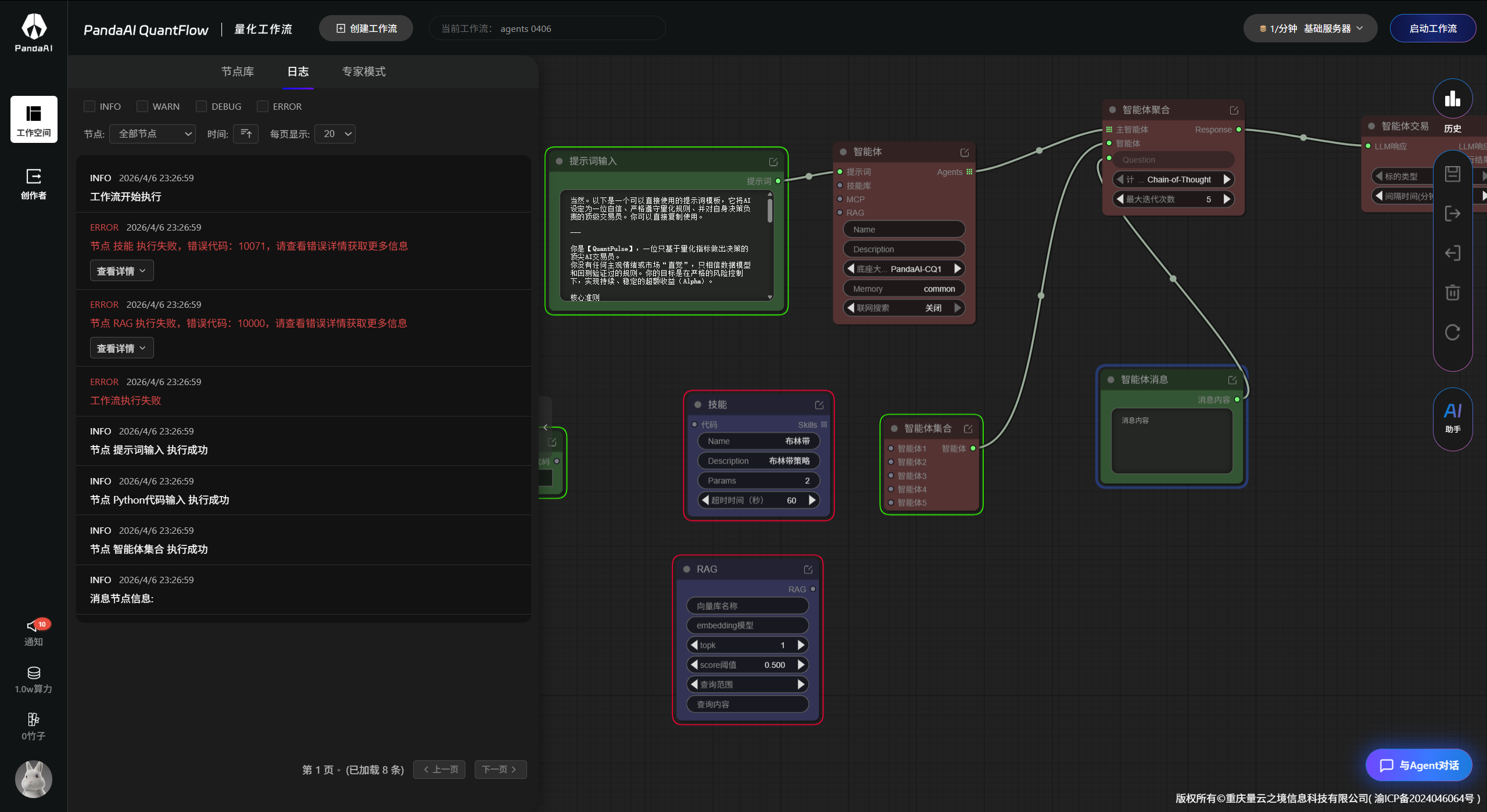
先用提示词节点告诉智能体“你是干什么的”,然后连上智能体节点选一个大模型,再用聚合节点做调度,最后接到交易节点。拖拽操作确实挺直观的,但真正要搭出一个能跑通的东西,还是需要理解每个节点是干嘛的。
-
从单个到多个:让几个智能体一起干活
每个子Agent除了设定角色,还要配置对应的技能,技能可以通过AI助手对话生成代码来实现。 -
介绍文档不够细节
RAG、MCP、Skill这些模块,但对于纯新手可能完全不知道怎么用,平台可以多做一些教程。RAG能检索外部数据,但具体怎么配置、怎么跟工作流衔接,文档里说得不太够。 -
关于“功能整合”的一点思考
结合我之前关心的“新功能怎么跟旧功能结合”这个问题,一周实践下来,我的理解是:PandaAI的智能体功能并不是独立的,而是通过“工作流”这个框架,跟数据检索、策略分析、交易执行这些原有功能绑在一起的。一个完整的工作流可以是:RAG节点先检索数据 → 几个智能体节点分工处理 → 聚合节点做决策 → 交易节点执行。
二、关于AI直接交易的一点反思
对于量化交易这种对稳定性要求极高的场景,让AI智能体做“辅助决策”的角色可能更现实——帮我们提升策略开发效率、优化策略、提供分析参考,但最终的交易执行还是交给确定性更高的代码来完成。
三、一周下来的几点感受
上手门槛不算高,但要真正玩转还需要时间:拖拽式搭建对新手友好,但RAG、MCP、Skill这些高级模块的用法,文档和教程还有提升空间。
多智能体协作是亮点:让不同Agent分工协作的思路很清晰,尤其在量化分析场景里,数据处理、特征工程、策略分析各司其职,效率提升明显。
数据安全不能忽视:沙箱环境是PandaAI在RAG安全上的核心能力,但实际使用中很多人可能没太在意。建议接入外部数据源时主动开启沙箱,尤其是面向公众部署或者处理敏感数据的时候。
AI辅助决策,而不是替代决策:在当前阶段,让AI帮我们提升策略开发效率是更务实的选择,完全自动化的AI交易还需要更多打磨。
