我们刚刚开始接触量化交易时,常常想要把量化交易中的每一个细节及其原理弄清楚,
比如:什么是量化多因子模型?因子具体做什么工作?因子与因子之间如何协作?模型是如何工作的?
今天,我把我自己打磨设计的一个比较完整的多因子量化交易模型拿出来跟大家分享,尽可能用最直白的语言让你快速理解,一个量化多因子模型到底是怎么运作的。
基本上,你可以把量化交易模型理解为这是一个“自动炒股机器人”。
一、策略要解决什么问题?
这个机器人的目标是:在几千只股票中,每天找出“大概率要涨”的股票买入,并在它“可能要跌”时卖出,从而赚取差价。
它不使用任何未来数据(不会“作弊”),只用今天之前的信息做决策。
二、机器人用了哪些“因子”来判断股票?
因子就是机器人用来衡量股票好坏的“指标”或“打分项”。它一共计算了8个基础因子,然后合并成一个总分。
- 价格偏离因子(price_deviation)
怎么算的:先计算一个“复合均价”(把最近60天、8天、3天的移动平均再平均),再减去“成交量加权均价”(类似每股平均成交价)。
通俗理解:如果当前价格比“长期平均成本价”高很多,说明股票可能过热;低很多可能被低估。
- 流动性因子(lfs_level)
怎么算的:根据每天的换手率(成交股数/流通股数)通过一套递归公式算出0~100的值。
通俗理解:衡量股票“交易活跃度”和“资金进出流畅度”。数值越高,说明流动性越健康。
- 流动性变化(lfs_change)
怎么算的:流动性因子最近5天的变化量。
通俗理解:如果流动性突然大幅提升,可能有大资金进场。
- 趋势强度(trend_strength)
怎么算的:当前价格相对于20日均线的偏离程度,再乘以波动率(ATR)与价格的比值。
通俗理解:既看价格是否站上均线(趋势向上),又看波动是否剧烈。值越大,上涨趋势越强。
- 量价相关性(volume_price_corr)
怎么算的:最近20天里,每天收益率与对数成交量的相关系数。
通俗理解:如果上涨时放量、下跌时缩量(正相关),说明趋势健康;如果上涨缩量、下跌放量(负相关),可能快要反转。
- 成交量突变(volume_surge)
怎么算的:当天成交量除以过去20天平均成交量,再减1。
通俗理解:突然放出比平时大20%以上的量,表示有异动。这个因子在策略里没有直接用于买卖,而是辅助判断。
- 反馈强度(feedback_strength)
怎么算的:过去20天里,流动性变化与股票收益率的相关性。
通俗理解:如果流动性改善时股价也在涨,说明资金流入推动上涨,形成正向反馈;反之则可能是骗线。
- 流动性极端偏离(lfs_extreme)
怎么算的:当前流动性因子值,减去过去60天的平均值,再除以标准差。
通俗理解:衡量流动性是否异常高或异常低。如果偏离超过2.25倍标准差,机器人会强制卖出(担心物极必反)。
三、这些因子是怎么合作打分的?
机器人不会只看一个因子,而是把以上8个因子组合成一个总分。步骤是:
第一步:标准化
每个因子的数值范围不一样(比如有的0100,有的-55)。机器人用过去120天的数据,把每个因子转换成“标准分”(大概在-3到3之间),这样不同因子可以公平相加。
第二步:分成两组
基础组:价格偏离 + 流动性水平 + 流动性变化(各占1/3权重)
增强组:趋势强度(0.2) + 量价相关性(0.2) + 反馈强度(0.3) + 流动性极端偏离(0.3)
第三步:计算基础分和增强分
基础分 = (价格偏离标准分 + 流动性标准分 + 流动性变化标准分) ÷ 3
增强分 = 趋势强度标准分×0.2 + 量价相关性标准分×0.2 + 反馈强度标准分×0.3 + 流动性极端偏离标准分×0.3
(注意:每个增强分会被限制在-11或-22之间,防止个别因子过分极端)
第四步:总分 = 基础分 + 增强分
第五步:根据大盘状态调整
机器人会看大盘指数(上证000001.SH) 的状态:
牛市或超卖反弹:调整系数 = 1(总分不变)
熊市:调整系数 = 0.5(总分打五折,防止在熊市乱买)
中性:系数 = 1
最终得到 “调整后总分”。
四、机器人如何根据总分决定买卖?
- 每天动态计算“买入门槛”和“卖出门槛”
机器人会回顾过去120天所有股票的总分,然后:
买入门槛 = 总分排在前30%的位置(比如过去总分大于0.6才算高)
卖出门槛 = 总分排在最后20%的位置(比如小于-0.4就算低)
这样门槛会随市场环境变化,牛市门槛自动提高,熊市门槛自动降低。
- 生成原始信号
如果某只股票的调整后总分 > 买入门槛 → 信号 = +1(想买)
如果调整后总分 < 卖出门槛 → 信号 = -1(想卖)
其他情况 → 信号 = 0(不动)
- 特殊情况修正
如果一整段时间都没有出现买入信号,机器人会用固定门槛0.2来补一些买入信号(防止策略彻底躺平)。
如果流动性极端偏离 > 2.25(标准分),强制发出卖出信号(-1),因为过于极端往往回调。
- 延迟一天执行(防止用今天收盘价作弊)
今天产生的信号,明天开盘后才真正交易。所以代码里用了 signal_lag(昨天的信号今天用)。
五、实际买卖操作细节(每天一次)
准备工作
初始资金:1亿元。
可买股票池:从A股中选了前500只(剔除停牌、ST等)。
每只股票最多投入当前现金的2%,最多同时持有10只。
卖出流程(优先执行)
检查昨天信号为-1的股票。
如果手里有这只股票:
获取当前价格,如果股价没有跌停(能卖出),就全部卖掉。
卖出得到的现金加到账户里。
记录这笔交易:卖了多少钱、赚了或亏了多少。
买入流程
检查昨天信号为+1的股票,且手里还没持有这只股票。
把这些候选股票按“调整后总分”从高到低排序,取前10名。
对每一只:
检查是否涨停、停牌(涨停买不进,停牌不能买)。
计算最多能买多少:当前现金 × 2% ÷ 当前股价,然后向下取整到100股的倍数。
如果钱够,就买入,现金减少,记录持仓。
每天收盘后记录
计算当天总资产 = 现金 + 所有持仓股票的市值。
保存下来,用于最后看收益曲线。
六、风险控制措施(防止大亏)
不重仓单只股票:每只最多2%仓位,即使全买满10只也只有20%仓位,留有大量现金。
避开涨跌停和停牌:涨停买不进、跌停卖不出,策略会跳过。
熊市减半信号强度:大盘不好时,总分打五折,减少买入冲动。
流动性极端偏离强制卖出:防止流动性突然崩盘。
只用过去数据:所有统计(均值、标准差、分位数)都只用历史日期的数据,没有未来信息。
七、整个策略的“思考过程”举例
假设今天是2024年5月20日:
机器人拿到昨天(5月19日)所有股票的数据。
对每只股票计算8个因子,标准化,算出调整后总分。
对比过去120天(约6个月)的总分分布,得到今天的买入门槛=0.5,卖出门槛=-0.3。
股票A总分=0.8 → 买入信号+1;股票B总分=-0.6 → 卖出信号-1。
等到今天开盘后:
先卖出股票B(如果持有),全部清仓。
再看股票A:如果没持有,且没涨停/停牌,就用现金的2%买入。
收盘后记录总资产。
八、这个策略的优缺点(简单总结)
优点:
多因子打分,不依赖单一指标,比较稳健。
动态调整门槛,能适应不同市场环境。
风险分散,仓位控制严格。
缺点:
计算复杂,需要大量历史数据。
牛市可能跑不过满仓指数(因为仓位低)。
参数(如移动平均天数、权重等)是事先固定的,不一定总是最优。
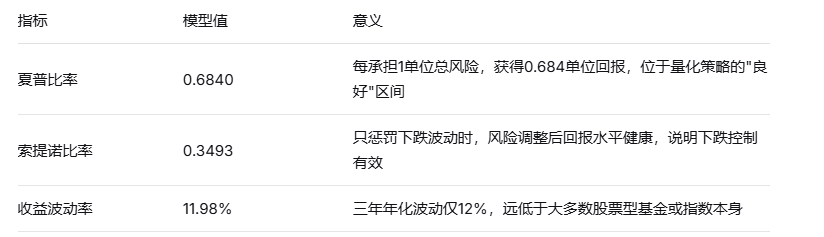
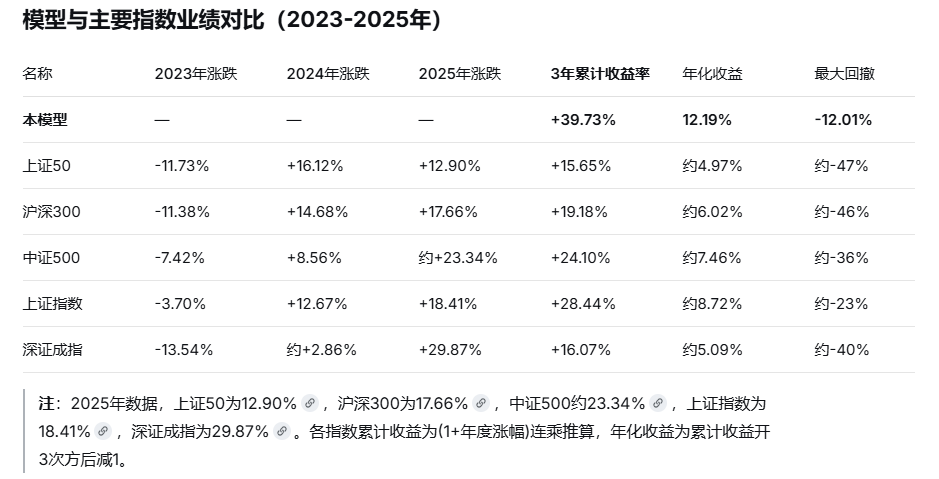
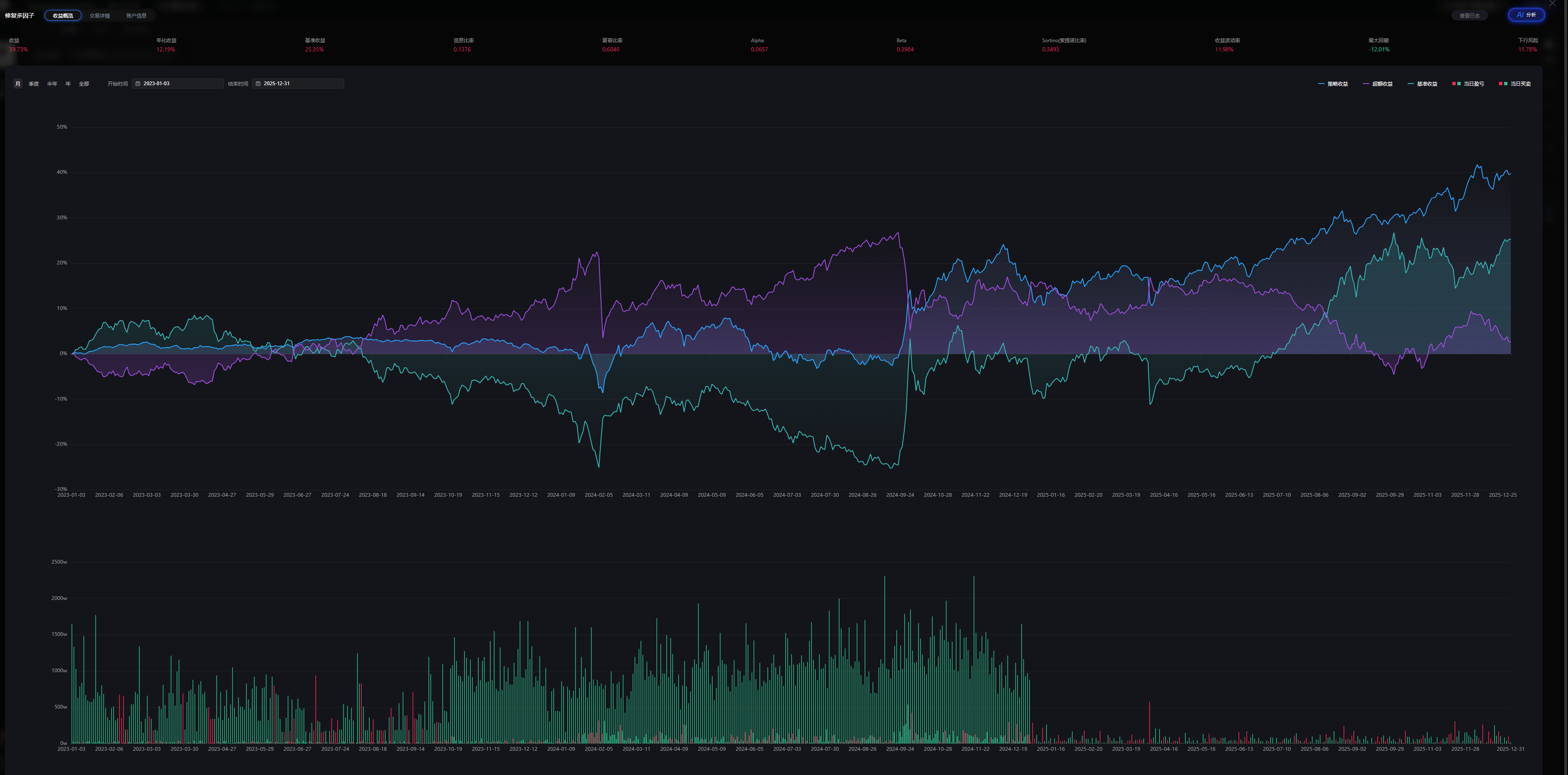
通过用过去3年的历史数据回测,我们可以得出对该模型的一个简单的综合评价:该量化多因子模型用市场一半的波动,赚出了跑赢所有主流指数的收益"——这正是该量化模型最值得肯定的成就。
一、收益与风险的平衡:模型跑赢所有主流指数
从绝对收益看,模型以39.73%的总收益率位居第一。上证指数累计+28.44%,中证500累计+24.10%,沪深300累计+19.18%,深证成指累计+16.07%,上证50仅+15.65%。
更关键的是,模型的年化收益为12.19%,这意味着平均每年12%的稳健复利,在三年包含2023年熊市和2024年剧烈波动的市场中做到这一点,实属不易。
二、风险控制:最大回撤-12.01%,远优于指数的极端跌幅
这是模型最核心的优势之一。
A股在回测期内经历了两次极端下跌:2024年初上证50一度较2021年高位累计下跌近50%;2023年沪深300全年跌11.38%,深成指全年跌13.54%。各指数最大回撤均达-30%至-50%,而模型的最大回撤仅为-12.01%。
换句话说,模型在指数腰斩级别的极端下跌中,最多只回撤了12%——这背后体现的是策略中多重风控设计的有效性:低仓位限制、流动性极端偏离强制卖出、熊市信号减半、避开涨跌停股票等措施,共同构筑了一道风险防火墙。
三、超额收益能力:信息比率0.1376,Beta仅0.3984
Beta = 0.3984:模型的波动性只有市场整体波动的大约40%。当指数大涨时模型不会涨到天上去,但当指数大跌时模型跌得也少得多——这种"低Beta"特征正是模型稳健表现的核心来源。
Alpha = 0.0657:在承担仅0.4倍市场风险的前提下,模型还额外创造了6.57%的年化超额收益。通俗理解:如果市场本身每年提供X%的回报,模型在只承担市场40%风险的同时,还多赚了6.57%。这是策略多因子打分能力的直接体现。
信息比率 0.1376:模型相对于基准(用户代码中基准为上证指数)的超额收益波动性较低,说明超额收益的来源相对稳定而非偶然。
四、策略稳健性:夏普0.6840,索提诺0.3493,收益波动率仅11.98%
索提诺比率0.3493高于许多传统多头策略,表明模型在下跌风险控制上的投入确实产生了回报。收益率11.98%的低波动率意味着收益曲线相对平滑,投资体验更好,心理压力更小。
最后,我们再来总结一下多因子模型的整体架构:
🤖 什么是量化交易?
量化交易简单来说,就是把人的投资想法,通过编写代码,变成计算机可以自动执行的规则–。
这个过程包含两个阶段:
回测:用历史数据模拟运行这个程序,检验它在过去会不会赚钱。就像用游戏机玩过去几个月的股票“模拟人生”。
实盘:如果回测效果不错,就把这个程序直接接入券商的真实账户,让它代替人执行–。
🔌 连接现实:Panda框架与数据
这个机器人的“大脑”是用Panda框架搭建的,它的“眼睛”和“手”则依赖 panda_data 和 panda_backtest 模块来感知市场并执行操作。panda_data负责获取行情和股票列表-13-13,panda_backtest则负责模拟成交、管理资金和账户等所有交易细节。
🧱 机器人的“骨架”:生命周期函数
Panda框架的核心是事件驱动,它用几个关键函数搭建起程序的骨架-1,让机器人在规定时间做规定动作。

🏗️ 拆解机器人:代码结构分析
有了以上认知,再来看整个策略的逻辑框架,就清晰多了。
1,准备工作:导入工具包与全局参数
导入 panda_backtest(交易框架)和 panda_data(行情数据)等包。
设置初始资金(1亿)、各计算参数和买卖阈值,所有参数都以 PARAMS、DYNAMIC_THRESHOLDS 这样的字典集中管理。
2,机器人启动 (initialize函数)
基础配置:设置初始资金、策略参数。
获取全市场股票:用 panda_data.get_stock_detail 获取所有股票代码,并选取前500只构建备选池。
加载历史数据:指定“训练期”(2023年全年)和“回测期”(2024-2025年)。调用 panda_data.get_market_data 加载相应日期内备选池的所有股票数据。
计算所有信号:
调用 calculate_factors() 计算8个基础因子。
调用 calculate_market_state() 获取大盘状态。
调用 generate_signals() 计算全样本的最终信号。
准备回测数据:只保留“回测期”的数据,并将买入/卖出信号向后平移一天,避免使用未来数据。
数据交接:将处理好的信号(context.signals)和日期列表(context.dates)存到 context 对象,供其他函数使用。
3,机器人大脑 (handle_data函数)
按日期顺序,获取当天的信号。
执行卖出:检查当天是否有卖出信号,如有则清仓对应股票,并将现金加回账户。
执行买入:检查当天是否有买入信号,按“总分”排序后,对符合条件的股票,最多投入现金的2%买入。
4,收盘结算:调用 _record_daily_value() 记录当日总资产。
每日结算 (after_trading函数)
收盘后,打印当日账户总权益和持仓情况。
5,辅助模块
calculate_factors:因子计算模块,策略的智慧核心。
rolling_normalize:数据归一化处理,让不同因子可对比。
generate_signals:综合所有信息,生成买卖信号。
_record_daily_value:记录资产变动,用于绩效分析。
💡 如何真正理解这段代码?
先明确角色,再梳理数据流:理解 initialize 是准备,handle_data 是核心,before_trading 和 after_trading 是辅助。
带着疑问去思考:每看到一个计算(如 calculate_lfs),就问自己:“为什么需要这个?”,“它想描述什么市场现象?”。
关注防未来信息与动态门限:观察它如何避免未来数据(signal_lag),并研究 generate_signals 中的动态门限,这是策略适应市场的关键。
从整体到局部:先理解一个因子如何从原始数据被加工成最终的交易信号,再深入到具体的数学公式。
🎓 举一反三:如何自己写一个新策略?
这套代码的结构是通用的,你完全可以修改它以创建自己的策略。
改变交易标的:修改 symbol_list 为期货、可转债或自定义的股票池,并相应调整 panda_data.get_market_data 的参数。
修改核心逻辑:重写 generate_signals 或 calculate_factors 函数。比如,可以只用一个简单的“金叉”信号来替换复杂因子-。
调整买卖规则:修改 handle_data 函数中的仓位比例(如2%)、选股数量(如前10)等。你也可以在 initialize 中设定滑点和手续费,让回测更真实–13。
增加风险控制:在 handle_data 的买入环节增加过滤条件,或借助 order 对象实现止损止盈-1。
