一、为什么这个工作流让人兴奋
传统量化研究的痛点:
- 跨工具割裂:因子分析在 Notebook,回测在另一个系统,来回倒数据
- 迭代慢:改一个参数要重跑一遍流程,等待时间长
- AI 没有融入:策略想法还是靠人工翻译成代码,门槛高
Panda 的这套工作流做对了三件事:
- 同一画布:因子分析节点和回测节点并列存在,数据直接流通,无需导入导出
- AI 接入在源头:策略描述 → AI 自动生成因子代码,不是事后辅助
- 可视化 DAG:整个研究流程像搭积木,每个节点职责清晰,改一处全图更新
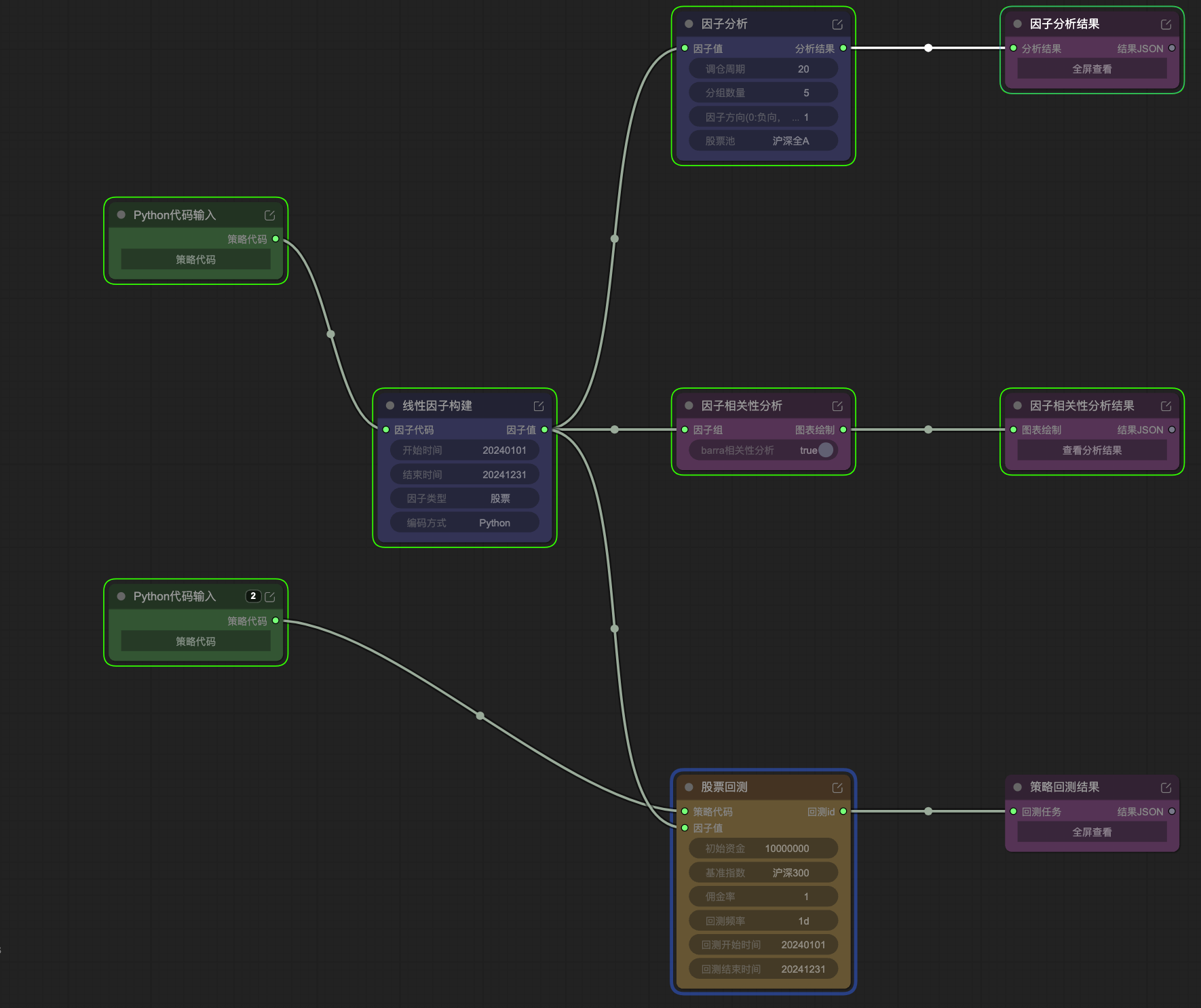
二、工作流全貌(抽象步骤)
从图中提炼出的标准流程,分为 三个阶段、七个步骤:
[Phase 1: 策略描述]
Step 1. 用自然语言向 AI 描述多因子策略逻辑
→ AI 生成 Python 因子代码(策略代码节点)
[Phase 2: 因子构建与分析]
Step 2. 线性因子构建 — 定义时间范围、股票池、编码方式
Step 3. 因子分析 — 分层回测、IC/IR 计算
Step 4. 因子相关性分析 — Barra 体系多因子去相关分析
Step 5. 查看分析结果 — 全屏可视化,判断因子质量
[Phase 3: 策略回测]
Step 6. 股票回测 — 接入因子值,配置资金/基准/频率
Step 7. 回测结果查看 — 收益曲线、Sharpe、最大回撤等
关键设计:Phase 2 和 Phase 3 在同一画布上并行存在,同一份「因子值」数据从线性因子构建节点分叉,同时流向「因子分析」和「股票回测」两个下游节点。
三、节点详解
3.1 Phase 1 — AI 生成策略代码
输入:自然语言策略描述(Prompt)
示例 Prompt(多因子量化策略):
多因子量化策略,包含趋势、反转、波动三类因子,采用动态权重、多空组合和风险控制机制,输出稳定 Alpha 策略。
一、因子构建:
- 趋势因子(Trend):
RANK(RETURNS(CLOSE,20)) * RANK(RETURNS(CLOSE,60)) * RANK(RETURNS(CLOSE,120))- 反转因子(Reversal):
* RANK(RETURNS(CLOSE,5))(负向)- 波动率因子(Volatility):
* RANK(STD(RETURNS(CLOSE,20)))二、数据处理:截面标准化(Z-score)、横截面去异常值
三、因子融合:Alpha = 0.5 × Trend + 0.3 × Reversal + 0.2 × Volatility
四、动态权重机制:市场趋势行情时 Trend 权重升至 0.6;震荡市时 Reversal 升至 0.4;高波动时降仓至 70%
五、组合构建:Alpha Score 排名,分 5 组,多头 Top 20%,空头 Bottom 20%
六、调仓:周期 20 天,等权配置
七、风控:最大回撤 >10% 降仓 50%;剔除波动率最高 20% 资产;去除因子排名 Top/Bottom 5%;T+1 执行
八、输出:累计收益曲线、Sharpe Ratio、最大回撤、分组收益(5 组)、Rank IC 与 IC IR
输出:两份 Python 策略代码(一份给因子分析用,一份给回测用),分别接入两条并行链路
3.2 Phase 2 — 因子构建与分析链路
节点 A:线性因子构建
| 参数 | 配置值 |
|---|---|
| 开始时间 | 20240101 |
| 结束时间 | 20241231 |
| 因子类型 | 股票 |
| 编码方式 | Python |
| 股票池 | 沪深全 A |
输出:标准化因子值(截面,每日)
节点 B:因子分析
| 参数 | 配置值 |
|---|---|
| 调仓周期 | 20 天 |
| 分组数量 | 5 组 |
| 因子方向 | +1(正向)/ -1(负向) |
| 股票池 | 沪深全 A |
输出:IC 序列、IR、分组收益、因子衰减曲线
节点 C:因子相关性分析
| 参数 | 配置值 |
|---|---|
| 分析方式 | Barra 相关性分析 |
作用:检测趋势/反转/波动率三因子之间的多重共线性,确保因子组合有效分散
输出:相关性热力图、因子暴露度分析结果(JSON)
3.3 Phase 3 — 策略回测链路
节点 D:股票回测
| 参数 | 配置值 |
|---|---|
| 初始资金 | 10,000,000 元 |
| 基准指数 | 沪深 300 |
| 杠杆率 | 1(不加杠杆) |
| 回测频率 | 1d(日频) |
| 回测开始时间 | 20240101 |
| 回测结束时间 | 20241231 |
输入:策略代码 + 因子值(直接从线性因子构建节点流入)
输出:回测任务 ID → 连接回测结果节点
四、数据流图(简化版)
AI 策略 Prompt
│
▼
Python代码输入 ──────────────────┐
│ │
▼ │
线性因子构建 │
(20240101~20241231) │
│ │
因子值 │
┌──┴──┐ │
│ │ │
▼ ▼ ▼
因子分析 因子相关性分析 股票回测
│ │ (接因子值 + 策略代码)
▼ ▼ │
分析结果 相关性结果 ▼
(IC/IR) (Barra热力图) 回测结果
(Sharpe/收益曲线)
核心设计:因子值在「线性因子构建」节点出来后 同时 流向分析和回测,无需拷贝数据,天然一致性。
五、为什么这个工作流「丝滑」
5.1 零数据搬运
过去:因子分析完导出 CSV → 回测系统读取 → 格式对齐 → 再跑
现在:一个节点的输出直接连到下游,数据格式和时间对齐由平台保证
5.2 AI 压缩了「想法到代码」的距离
最耗时的不是跑代码,是「把策略想法翻译成可运行代码」。
AI 把这个过程从 小时级 压缩到 分钟级:
- 用业务语言描述策略
- AI 同时生成因子代码 + 回测代码
5.3 改参数即改节点,影响可控
想测试「调仓周期从 20 改到 10」——只改因子分析节点的参数,上游因子值不变,下游立即更新
想换股票池——只改线性因子构建节点,分析和回测同步更新
5.4 分析与回测相互验证
同一时间窗口(2024年)、同一股票池(全 A):
- 因子分析的 IC/IR 是「因子质量」的信号
- 回测的 Sharpe/收益是「策略实盘可行性」的验证
两者都通过 → 策略有信心上实盘
六、典型使用场景
场景 A:快速验证新因子想法
1. 写 Prompt:「用十日换手率的倒数作为流动性因子,测试其在全 A 的选股效果」
2. AI 生成代码 → 线性因子构建(设置时间范围)
3. 直接跑因子分析,看 IC 是否显著(>0.02)
4. IC 显著 → 接入回测验证收益曲线
5. 回测 Sharpe > 1 → 进入下一步精修
场景 B:多因子权重调优
1. 基础多因子策略已跑通
2. 修改 Prompt 中的权重(Trend 0.5 → 0.7)
3. 因子相关性分析看 Barra 暴露变化
4. 回测对比不同权重下的 Sharpe 差异
5. 选最优权重配置
场景 C:历史区间轮换验证(Walk Forward)
1. 复制当前工作流
2. 修改线性因子构建的开始/结束时间(换时间窗口)
3. 三个历史区间各跑一次
4. 对比三个区间的 IR 和 Sharpe,验证策略稳健性
七、使用技巧
Prompt 写作要点
好的策略 Prompt 包含以下结构:
1. 策略类型声明(多因子/单因子/择时)
2. 因子定义(公式、方向、组合权重)
3. 数据处理方式(标准化、去异常值)
4. 组合构建规则(分组数量、多空方式)
5. 调仓频率和资金管理
6. 风控规则(回撤线、波动过滤)
7. 期望输出指标
越具体,AI 生成的代码越准确,人工修改量越少。
节点参数调优顺序
先定范围 → 先跑小样本(1年)确认节点连通
验证因子 → 看 IC > 0.02,单调性良好
验证策略 → Sharpe > 0.8,最大回撤 < 15%
扩时间范围 → 跑 3~5 年验证稳健性