这周已经是我使用 PandaAI 平台学习和做策略开发的第 5 周了。
前几周更多是在熟悉平台工作流、AI 助手、基础回测和因子分析链路;本周开始,我把重心放在了因子挖掘功能里的机器学习工作流体验上,主要是跟着视频和参考文档,尝试用 XGBoost、LightGBM 这类模型做一版“机器学习辅助挖掘多因子”的实践。
整体感受是:PandaAI 把机器学习因子挖掘的门槛明显降下来了。以前如果自己本地从零搭一套训练、打分、回测链路,步骤很多;现在用工作流把节点串起来,至少可以先把完整流程跑通,再逐步调特征、调参数、看因子分析结果和回测结果。
一、本周主要在做什么
本周我主要还是在尝试机器学习方向的因子挖掘。
前面学习过程中,我也接触过单因子和多因子工作流,但这周的重点已经不再是这两部分本身,而是进一步往前走,开始尝试:
- 把一组基础特征输入给机器学习模型;
- 用模型自动组合这些特征,生成机器学习因子;
- 再接因子分析、相关性分析和回测,观察整条链路的表现。
视频里对因子挖掘功能的介绍,我自己的理解可以概括成三点:
- 因子可以自己手工挖掘,也可以借助 AI 或机器学习模型辅助挖掘;
- 平台的重点不只是“生成一个因子”,而是把公式输入、因子构建、因子分析、结果查看这些环节都串起来;
- 机器学习工作流本质上是把一组原始特征喂给模型,让模型去学习更复杂的非线性组合关系,然后再用和单因子、多因子类似的方式做因子分析和回测。
这周我实际跑的重点,就是第三类:非线性机器学习模型工作流。
如果和我一样,刚开始接触这部分内容,我觉得下面两个教学视频很值得先看一遍:
我自己这周也是边看视频、边对照平台工作流、边实际尝试,才逐步把这条机器学习因子挖掘链路跑通。
二、本周搭建的机器学习工作流
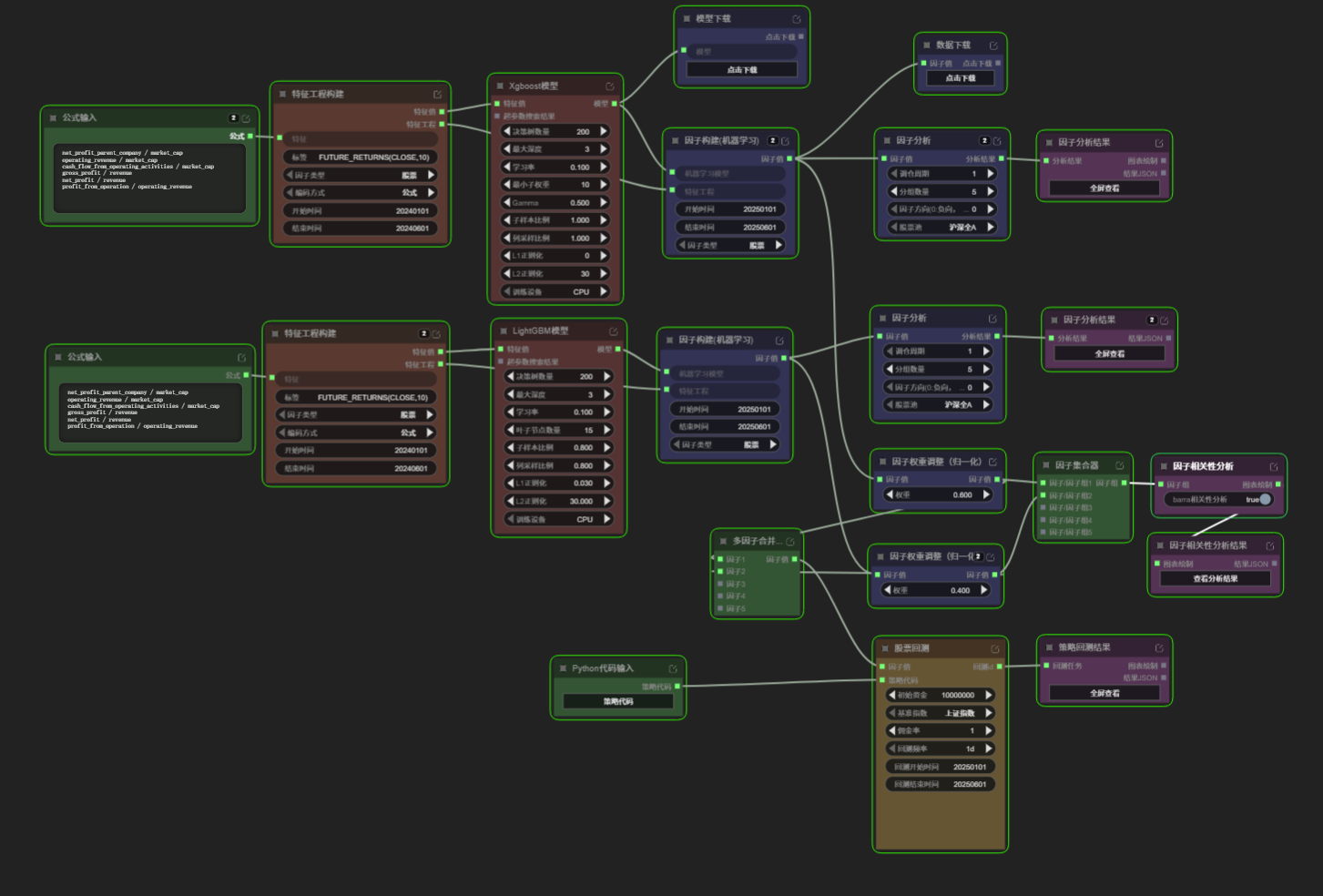
我这周做的是一版比较典型的“基本面质量/价值”方向机器学习工作流,大致链路是:
公式输入 -> 特征工程构建 -> XGBoost模型 / LightGBM模型 -> 因子构建(机器学习) -> 因子分析 -> 因子权重调整(归一化) -> 多因子合并 -> 因子相关性分析 -> 股票回测
当前我主要输入的是几类基础基本面特征,例如:
net_profit_parent_company / market_cap operating_revenue / market_cap cash_flow_from_operating_activities / market_cap gross_profit / revenue net_profit / revenue profit_from_operation / operating_revenue
标签方面,当前尝试使用的是:
FUTURE_RETURNS(CLOSE,10)
我自己的思路是:
- 先不用太复杂的深度学习模型;
- 先用树模型,把工作流、输入特征、因子分析和回测链路跑通;
- 先看机器学习能不能在“手工特征”的基础上,学习出更好的非线性组合关系。
三、为什么会想用“模型自动挖掘因子”,而不是只做手工挖掘
这个问题是我这周体会最深的一点。
1. 手工挖掘的优点
手工挖掘因子的好处很明显:
- 因子逻辑更清晰,自己知道它到底在表达什么;
- 可解释性更强,出了问题更容易定位;
- 更容易做正负方向判断和经济意义验证;
- 更适合做第一轮研究和建立直觉。
比如“低波动放量突破”“动量”“反转”“毛利率”“现金流质量”这些,手工公式写出来以后,至少能先明确自己在研究什么。
2. 机器学习自动挖掘的优点
但自动挖掘也有手工方式很难替代的地方:
-
能学习非线性关系
很多特征对收益的影响,不是简单加减乘除就能表达的。像
XGBoost、LightGBM这类模型,更容易学到特征之间的组合关系和交互关系。 -
能提高特征组合效率
手工多因子通常是“我先想几个因子,再加权组合”;机器学习更像是“我先给一组候选特征,让模型自己决定怎么切分和组合”。
-
更适合做特征筛选和第一轮探索
有时候不是完全指望模型直接给出一个完美 Alpha,而是先借模型看看“哪些输入更有信息量、哪些特征组合可能有效”。
-
对新手更友好
对我这种刚开始接触系统化量化研究的人来说,平台把机器学习工作流节点封装好以后,能明显降低上手成本。至少可以先跑通,再逐步理解里面每一步在做什么。
3. 机器学习自动挖掘的缺点
但缺点也很现实,而且本周我已经碰到了:
-
可解释性变弱
手工因子我知道自己在研究什么,机器学习因子很多时候更像“模型输出的一个综合信号”,解释难度会高很多。
-
容易过拟合
如果训练区间、打分区间和回测区间处理不好,或者参数太激进,回测可能看着不错,实盘不一定能复现。
-
结果容易看起来很“像提升了”,但不一定真的有增量
有时候机器学习只是在重复表达你原来的手工特征,只是换了一种非线性形式,不一定真的挖出了新的东西。
-
对研究流程要求更高
手工因子研究错了,通常是“因子逻辑不强”;机器学习研究错了,可能是特征、样本切分、参数、标签、股票池、回测对齐任何一个地方出了问题。
我的体会是:
手工挖掘更像“自己提出假设”,机器学习挖掘更像“让模型帮我组合和试错”。
两者不是替代关系,更适合配合使用。
四、本周看视频后,对因子挖掘功能的理解
这周视频主要聚焦在因子挖掘功能本身,我自己整理下来,印象比较深的是下面几点。
1. 单因子工作流适合打基础
单因子链路最清晰:
公式输入 / Python代码输入 -> 线性因子构建 -> 因子分析 -> 因子分析结果
这一步适合先确认:
- 因子方向对不对;
- IC 有没有基本统计意义;
- 分组收益和多空组合是否有区分度;
- 参数设置如调仓周期、分组数量、因子方向对结果的影响。
2. 多因子工作流重点在“权重”和“相关性”
多因子不是简单把多个因子值线性加起来,所以视频里专门强调:
- 要加权重节点;
- 要看因子相关性;
- 要避免多个高度相似的因子重复叠加。
这一点我本周在机器学习工作流里体会特别深。
3. 非线性机器学习工作流是“多特征 -> 模型 -> 因子”的过程
机器学习工作流的关键不是“模型名字很高级”,而是:
- 用什么输入特征;
- 标签怎么设计;
- 训练期和样本外期怎么切;
- 模型参数怎么控制;
- 最终输出的机器学习因子能不能通过因子分析和回测验证。
也就是说,机器学习节点并不是替代研究,而是把研究重点从“单个手工公式”转到了“特征工程 + 样本切分 + 模型约束 + 结果验证”。
五、本周遇到的主要问题
本周做这版机器学习工作流,最大的感受是:机器学习这条链路比我一开始想的要复杂很多。
虽然平台已经把很多节点封装好了,但真正在使用时,还是会碰到不少需要自己慢慢理解和消化的概念。
1. 需要更多资料和教程,继续学习机器学习和因子挖掘的相关知识
这周自己最大的真实感受是:
- 机器学习相关概念确实比较多;
- 不是把模型节点拖进去、连起来就结束了;
- 特征、标签、训练期、样本外期、模型参数、因子分析、回测这些环节,彼此都有关系。
目前我还是先以参考教程、先跑通流程、边做边理解为主。
很多东西现在还谈不上真正吃透,比如:
- 什么样的特征更适合喂给模型;
- 标签周期和调仓周期怎么配合更合理;
- 两个模型之间什么时候算互补,什么时候只是重复;
- 因子分析结果和实际回测结果为什么会不一致。
所以这周更像是在“先搭一版能运行的机器学习工作流”,然后在运行过程中逐步体会和学习,而不是已经进入非常成熟的优化阶段。
我也很希望官方后续能提供更多体系化、分层次的学习资料。
目前 B 站视频对我帮助很大,但视频整体还是偏概括、偏演示,很多知识点如果想真正吃透,还是需要更多更细的资料去配合学习。
2. 机器学习中的训练期、样本外期、回测期,最好增加一些提醒
本周在实践过程中,我越来越强烈地感觉到:
- 训练期、样本外期、回测期必须严格拆开;
- 这不是一个“细节问题”,而是机器学习因子研究里非常核心的问题;
- 如果这几段时间混在一起,结果很容易看起来不错,但其实不够真实。
这也是我这周学习机器学习工作流时,一个比较大的认识变化。
我觉得平台如果后续能在机器学习节点或者因子构建节点这里,增加一些更明显的时间区间提醒,会对新手特别有帮助。
至少可以在运行前做一些简单校验,提醒用户当前训练期和样本外期是不是重叠了,避免因为时间区间选错,导致结果失真。
3. 多因子合并、因子集合器这两个节点的区别,还不够直观
这周在多因子组合和相关性分析环节,我对下面两个节点有些疑惑:
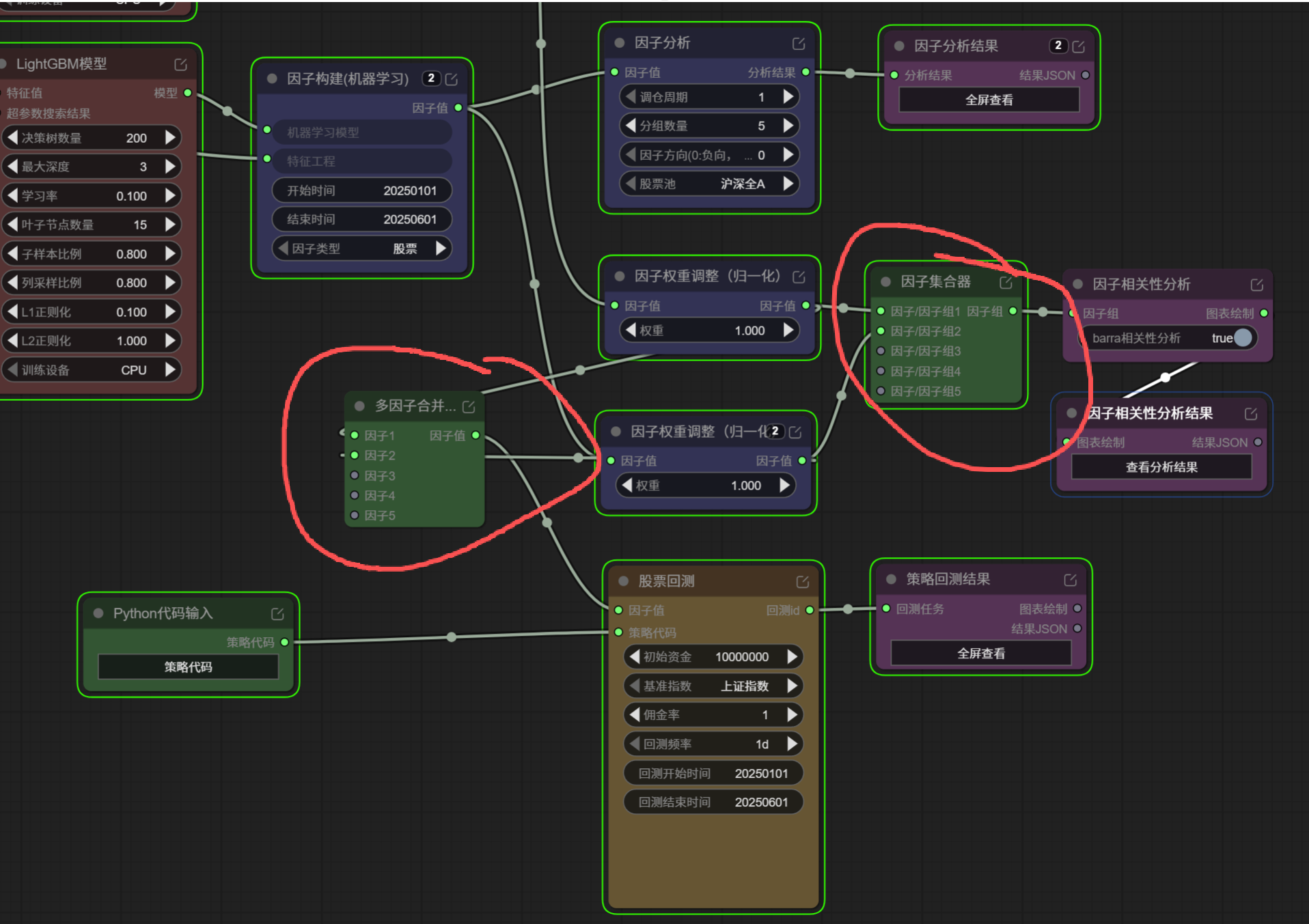
多因子合并因子集合器
目前我自己尝试下来,感觉这两个节点:
- 在相关性分析里似乎都可以作为输入;
- 在股票回测里好像也都能接后续节点;
- 但它们的设计目的和使用区别,文档里写得还不够细。
尤其是对于刚接触这部分功能的新手来说,更想知道:
- 什么时候应该用
多因子合并; - 什么时候应该用
因子集合器; - 两者在输出结果上到底有什么差异;
- 如果只是想把多个因子送进相关性分析或回测,应该优先选哪一个。
这一点如果官方后续能补一版更详细的节点说明,应该会很有帮助。
4. 导出的工作流没有包含回测代码,这个问题还是比较影响使用
这个问题我这周也还是遇到了。
目前的体验是:
- 导出的工作流里没有把回测代码一起带上;
- 重新导入工作流后,还需要重新把回测代码复制粘贴进去;
- 而且有时候不是在运行前就报错,而是等工作流跑到回测节点附近才提示代码问题。
这样带来的问题是:
- 前面节点已经消耗了算力;
- 到后面才发现代码节点缺内容或者报错;
- 对新手来说会有点莫名其妙,也比较影响体验。
我觉得这里如果能增加一个“运行前检测”的机制会更好,比如:
- 提前检查回测代码节点是否为空;
- 提前检查关键输入是否缺失;
- 在真正消耗算力前先做一次完整性校验。
5. 本周最典型的问题,出现在因子相关性分析里
根据我在 相关性问题.md 里记录的结果:
- 两个机器学习子因子之间的相关系数大约是
0.9566 - 说明这两个“机器学习因子”高度相似,信息重叠非常严重
- 它们与 Barra 风格因子虽然不是完全共线,但对杠杆、估值等风格已经有一定暴露
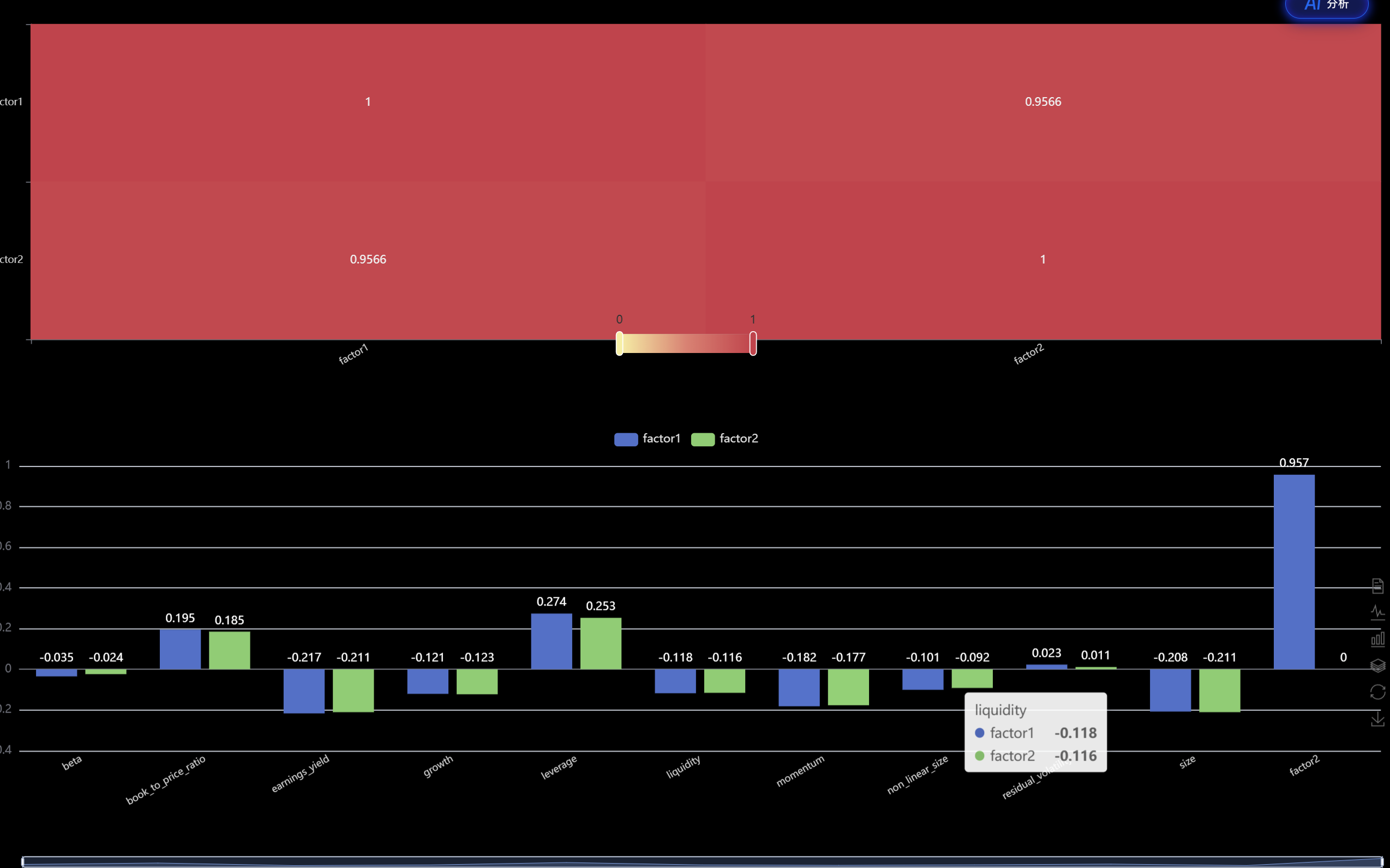
这件事对我有两个提醒:
1. 机器学习不是“上两个模型就一定更强”
我原来直觉上会觉得:
- 一个
XGBoost - 一个
LightGBM - 再把它们合并
应该比单模型更好。
但实际跑下来发现,如果:
- 输入特征完全一样;
- 训练区间完全一样;
- 两个模型都在学同一类信号;
那最后出来的两个因子很可能只是“长得不一样,本质上一样”。这时候再叠加,增量就有限。
2. 自动挖掘不等于自动去冗余
模型可以帮我做非线性组合,但不会自动告诉我:
- 这两个模型是不是学成了同一个东西;
- 当前信号是否已经过度偏向某种风格暴露;
- 是否应该只保留一个模型或者做去冗余处理。
所以相关性分析这一步,我觉得不是可选项,而是机器学习多因子工作流里非常重要的一步。
6. 还有一个实际问题:回测表现并没有因为用了机器学习就自动变好
这一点其实也很正常。
从这周自己的尝试来看,机器学习模型虽然搭起来了,但回测表现并没有自动进入“收益很好”的状态。原因我目前理解至少有几类:
- 特征还太少,模型学到的信息有限;
- 两个模型输出高度相似,组合增量不够;
- 当前参数、股票池、样本切分和回测节奏还需要继续优化;
- 机器学习因子虽然有一定信息量,但离“可稳定实战”还有距离。
这个过程也让我更接受一个现实:
机器学习工作流最大的价值,可能不是第一版就直接给我一个高收益策略,
而是帮我更快地发现“哪些特征有信息、哪些组合没必要重复、哪里还存在研究框架问题”。
六、本周的个人收获
本周最大的收获,不是“我已经做出了一个很强的机器学习策略”,而是我对平台里的因子挖掘链路理解更完整了。
具体来说有三点:
1. 把单因子、多因子、机器学习工作流的关系理顺了
我现在的理解是:
- 单因子适合先验证一个清晰逻辑;
- 多因子适合把几个互补因子组合起来;
- 机器学习更适合在一组候选特征基础上,尝试让模型学习更复杂的组合关系。
2. 知道了机器学习工作流里“研究重点”在哪
这周之前,我更关注模型名字;这周之后,我更关注:
- 特征输入质量;
- 标签是否合适;
- 不同阶段的时间切分是否合理;
- 因子相关性是否过高;
- 回测和因子分析是不是同一个节奏。
3. 对“手工挖掘 + 模型辅助挖掘”的组合方式更有感觉了
我现在更倾向于把机器学习理解成:
- 不是完全替代手工因子;
- 而是建立在手工特征基础上的进一步组合和增强;
- 先用手工逻辑保证经济意义,再用模型提升组合方式。
七、对平台功能的一些感受和建议
从体验上看,PandaAI 这套因子挖掘工作流对新手很友好,尤其是:
- 模板工作流可以直接上手;
- 公式输入、特征工程、模型训练、因子分析这些步骤都可视化了;
- 对比自己本地从零搭训练和回测环境,入门成本低很多。
同时我也有一些很真实的感受:
- 如果是第一次接触机器学习因子研究,还是很容易只盯着“模型参数”,忽略了样本切分和研究设计;
- 相关性分析、权重调整这些节点,真的不是装饰,实际用起来非常重要;
- 如果后续平台能在机器学习工作流上,进一步强化“样本外区间提醒、因子去冗余提示、风险暴露提示”,对新手会非常有帮助。
八、下周计划
下周我准备重点做下面几件事:
- 继续优化当前机器学习工作流,先把训练期、样本外期、回测期严格拆开;
- 对比单模型和双模型效果,确认两个模型是否有必要同时保留;
- 基于相关性分析结果,尝试做去冗余或只保留一个主模型;
- 继续补充特征,看看能否从“手工因子输入”里给机器学习模型更多有效信息;
- 继续看因子分析、回测和相关性结果,逐步形成自己的研究节奏。
小结
这周的体验让我更明确了一点:
PandaAI 的机器学习因子挖掘功能,不是“点一下按钮就自动出圣杯策略”,
而是给了我一个可以低门槛反复实验、逐步理解因子研究流程的工作台。
对我这种还在学习中的用户来说,这个过程本身就很有价值。
一方面,它让我能比纯手工更快地尝试非线性模型;另一方面,也让我更直观地看到机器学习因子研究里那些平时容易忽视的问题,比如样本切分、因子冗余、风格暴露和回测对齐。
本周算是把“机器学习工作流的第一版体验”走通了。虽然结果还远谈不上成熟,但确实把很多以前停留在概念层面的东西,真正跑成了一个完整流程。
