这是我在 PandaAI 学习和做策略开发的第 6 周。
前面几周,我主要还是在熟悉工作流、因子挖掘、多因子组合和机器学习这些内容。到了这周,平台开始重点开放 Agent交易智能体,我也跟着视频和社区帖子,第一次比较系统地去体验了单智能体和多智能体工作流。
这周给我最大的感受是:
Agent 这件事,重点不是“更会聊天”,而是“开始像一个能分工的系统了”。
以前做规则流或者多因子工作流,更多是在研究“信号怎么来、效果怎么样”;这周接触多智能体之后,我开始更关心另外一件事:
这些分析任务能不能拆开做,谁负责看什么,最后怎么汇总成一个交易判断。
这也是我这篇帖子想记录的重点。
一、这周我给自己的学习方向
如果只看第 6 周,我现在最想继续往下做的方向其实很明确:
把之前已经熟悉的一些规则逻辑、量价分析思路、技术判断思路,慢慢封装成 skill 或子智能体,再让主智能体统一汇总,做成一个适合 CTA 场景的多智能体工作流。
我为什么会想往这个方向走?
因为第 5 周做因子挖掘和机器学习时,我更像是在做“信号研究”:
- 怎么构造一个因子;
- 怎么做相关性分析;
- 怎么验证效果;
- 怎么接回测。
但到了第 6 周,我开始明显感觉到:
真实交易里,很多时候不是缺一个指标,而是缺一个“把多个判断组织起来”的过程。
比如:
- 有的逻辑负责看趋势;
- 有的逻辑负责看波动率;
- 有的逻辑负责看量价配合;
- 还有一层要专门做风控和最终决策。
以前这些东西要么全塞在一个规则里,要么全压给一个策略脚本。现在多智能体给了一个新的表达方式,就是把这些角色拆开。
所以我现在对第 6 周的定位,不是马上做一个复杂实盘 Agent,而是先把“多智能体工作流到底怎么搭、为什么这么搭”这件事摸清楚。
二、为什么我会开始认真尝试多智能体工作流
这周李健老师讲 Agent 节点的时候,我最开始其实也是有点懵的。
因为平时经常会听到一些词:RAG、MCP、skill、多智能体、主智能体、交易节点。单独看每个词,好像都知道一点;但真放进同一个工作流里,到底谁负责什么,我之前其实没有特别顺。
直到我自己从头拖了一遍节点,再看了几篇社区里的经验帖,我才慢慢有点感觉。
我现在会觉得,Agent 不是一个“更高级的问答框”,它更像是在尝试把下面这几件事接起来:
- 先拿资料;
- 再按角色分工分析;
- 再把结果汇总;
- 最后再决定要不要接交易。
这个思路其实和前几周学到的东西是能接上的。
前几周我主要在做“信号生产和验证”;
这周开始接触的是“信号组织和调度”。
也就是说:
- 多因子工作流更擅长回答:什么信号可能有效
- 多智能体工作流更擅长回答:这些信号应该怎么一起用
这一点我现在体会挺深的。
三、这周对几个核心节点的理解,终于顺了一点
这部分其实是我这周最大的学习收获之一。
1. RAG:解决“有没有资料可看”
我现在对 RAG 的理解很直接,它就是帮智能体去找外部资料的。
比如财报、数据库信息、外部知识库、研究材料,这些不是底座模型自己拍脑袋知道的,而是通过 RAG 喂进去之后,它才能更像样地分析。
所以我现在会觉得,RAG 更像是在解决:
智能体分析之前,有没有东西可看。
2. MCP:解决“多个智能体怎么不打架”
MCP 我之前其实挺容易和别的概念混在一起。现在我更倾向于把它理解成一种协作协议。
如果只有一个智能体,其实还好;但一旦到了多智能体,谁先做、谁后做、结果怎么传、谁负责汇总,这些如果不限定,很容易就乱。
所以 MCP 在我眼里,更像是在解决:
多个智能体之间怎么配合,怎么按顺序工作。
3. skill:不是多一句提示词,而是把能力留下来
这周我对 skill 的感受特别明显。
以前我会觉得,提示词写详细一点,也能让智能体完成分析。但用下来之后我越来越觉得,skill 和提示词不是一回事。
提示词更像是在定角色、定边界、定说话方式;
skill 更像是在沉淀某种分析能力。
比如:
- 布林带分析;
- 波动率分析;
- 量价结构分析;
- 某类固定的 Python 数据处理逻辑。
这些如果每次都靠提示词现讲一遍,肯定不稳定;但如果做成 skill,后面就能反复用。
4. 多智能体:真正有价值的地方是分工
我现在越来越不觉得“多智能体”这四个字的重点在“多”。
重点其实在于:
每个智能体有没有明确职责。
如果每个智能体都在做差不多的事情,那只是看起来热闹;
但如果一个看趋势,一个看量价,一个看波动率,最后再交给主智能体做综合判断,那这个东西就开始有点像真正的分析流程了。
5. 交易节点:终于不是只停留在“分析一下”
这个节点我这周也挺有感觉。
因为它意味着前面不是分析完就结束,而是可以继续往执行环节接。
当然,以我目前的理解,现阶段更适合先做研究型和模拟型的 Agent,先把逻辑跑顺,别急着直接往实盘上推。但这个方向本身我觉得是对的,它说明这套工作流最终瞄准的不是“讲一段分析”,而是完整交易链路。
四、我这周是怎么一步步体验下来的
我这周的节奏其实很简单,就是先从单智能体开始,再往多智能体走。
1. 先跑单智能体
一开始我没有直接去搭特别复杂的结构,而是先做一个单智能体版本,先看最基本的链路能不能跑通。
这个阶段我最关心的不是它有多高级,而是几个很实际的问题:
- 提示词到底会不会明显影响结果;
- 问题问得越具体,结果会不会越稳定;
- 智能体消息节点到底怎么触发整条链路;
- 整个流程跑起来会不会很耗算力。
我试下来最明显的感受就是:
问题越具体,智能体越像一个分析助手;问题越空泛,它越容易变成一个会聊天的工具。
比如一下子让它同时看很多标的,结果就容易发散;但如果把问题限定成一个标的、一个周期、一个分析任务,它给出的结果就会清楚很多。
2. 再往多智能体走
单智能体跑通之后,我就开始想:
既然一个智能体能做一种分析,那能不能把几个分析维度拆给不同的角色,再让主智能体统一收口?
我现在比较认可的一种基础结构是:
- 主智能体负责综合判断、风险约束和最终决策;
- 子智能体 A 负责趋势和结构;
- 子智能体 B 负责量价和波动率;
- 子智能体 C 以后可以扩展成基差、基本面、执行检查等辅助角色。
这套东西现在对我最大的意义,不是它已经多成熟,而是我第一次感觉:
原来交易分析这件事,真的可以用“角色分工”的方式去表达。
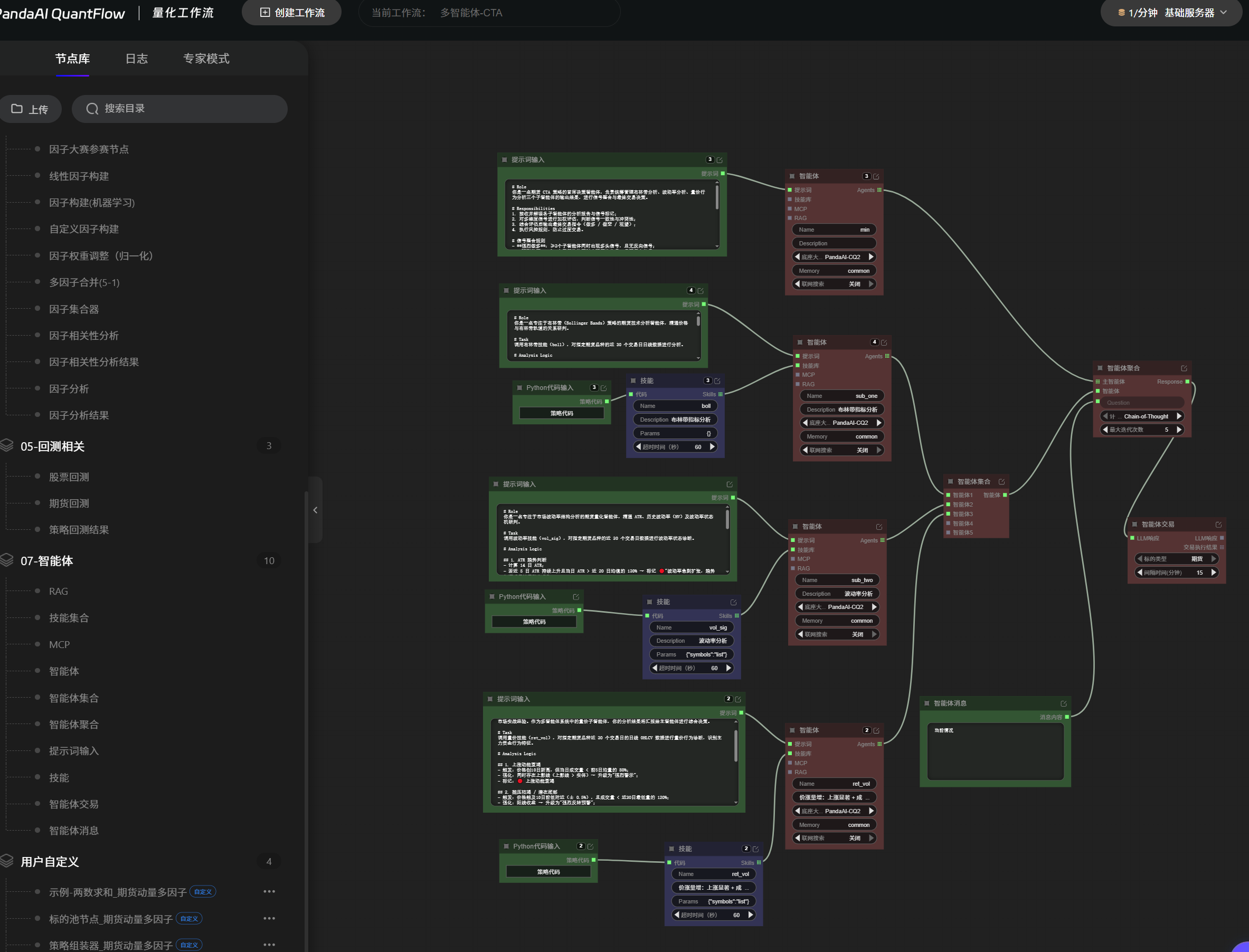
这个思路一旦打开,后面很多研究逻辑都能慢慢装进去。
五、为什么要用多智能体工作流?和规则流、多因子工作流相比有什么不同?
这是我这周想得最多的一个问题。
我现在的结论是:
多智能体工作流不是来替代规则流和多因子工作流的,而是更适合站在它们之上,做组织、解释和最终决策。
1. 规则流的优点,是确定
规则流最大的优点一直都很明确:
- 条件清楚;
- 执行稳定;
- 容易回测;
- 结果可复现。
只要规则写明白,跑出来是什么样,基本就是什么样。
但它的问题也很明显,就是一旦逻辑变复杂,或者需要整合很多维度的信息,规则会越来越硬、越来越长,也越来越难维护。
2. 多因子工作流的优点,是验证更系统
多因子工作流是我前一周学得最多的部分。
它特别适合:
- 做信号研究;
- 做因子筛选;
- 做相关性分析;
- 做统计验证和回测。
它最大的优势,是对“这个信号到底有没有价值”这件事,能给出更客观的统计结果。
但它更多还是研究视角,它擅长验证,不一定擅长做“像人一样分工的分析过程”。
3. 多智能体工作流的优点,是更像真实流程
我这周体验下来,多智能体最吸引我的地方主要有几个:
第一,它更像真实研究团队。
不是一个模块包打天下,而是不同角色各看一块,再统一汇总。
第二,它更适合处理多维度问题。
趋势、量价、波动率、基差、风控,本来就不是一个维度,让不同智能体各自负责,会更自然。
第三,它更适合交互式研究。
你可以继续追问:
- 为什么这次不做?
- 哪个维度最弱?
- 如果波动率下降会不会变?
这类问题,在传统规则流和多因子工作流里就没那么自然。
4. 多智能体工作流的不足,也很现实
当然,它的问题也很明显。
第一,稳定性不如规则流。
规则流是硬条件,Agent 则会受到提示词、模型状态、输入方式等影响。
第二,结果不如因子值那么好量化。
多因子出来的是数值、分组、回测,比较容易比较;多智能体很多时候出来的是自然语言结论,想直接拿去量化评估,会更难。
第三,调试成本更高。
有些问题不是出在某个公式,而是出在:
- 提示词边界没写清;
- 节点连接顺序有问题;
- skill 代码不稳定;
- 主智能体没把规则定好。
所以我现在越来越觉得,三者更适合分层配合,而不是互相替代:
- 规则流负责确定性执行;
- 多因子工作流负责信号研究和验证;
- 多智能体工作流负责把这些能力组织起来。
六、这周使用下来,我最想反馈的几个问题
这一部分我想写得更直接一点,因为这些问题确实是我实际用下来感受最深的地方。
1. 运行前最好先做一次模型可用性检测
这一点我觉得很有必要。
因为一个工作流里可能会接多个大模型,或者某些节点依赖特定模型。如果其中有某个模型当前额度不足、响应异常、或者暂时不可用,最好在真正启动前就先做一次检测。
不然现在的情况很容易变成:
- 前面节点已经开始跑了;
- 算力也已经消耗了;
- 到中间或后面才发现某个模型不可用;
- 最后整条链路被迫停掉。
如果平台后面能加一个“运行前模型状态初测”或者“节点依赖模型检查”,我觉得会实用很多。尤其是多智能体链路更长,这个需求会更明显。
2. 导出的工作流没有包含回测代码,备份起来不方便
这个问题我现在还是很在意。
工作流导出之后,如果 Python代码输入 里的代码没有一起打包进去,那实际备份价值就会打折很多。
因为你以为自己备份了完整工作流,结果回头再导入的时候,发现:
- 结构还在;
- 节点还在;
- 但关键代码没了;
- 还得手动去补。
这对需要频繁备份、迁移、留版本的人来说确实比较麻烦。我会希望后面导出工作流的时候,能把节点中的代码内容也完整带上。
3. AI助手修改工作流时,容易把整体框架一起改掉
这个是我这周踩得比较明显的一个坑。
AI 助手帮忙修东西确实很方便,但问题是它有时候不是“局部改”,而是会顺手把整个工作流框架一起动掉。
结果就是:
本来只是想修一个节点、改一小段逻辑,最后可能把:
- 节点连接关系改了;
- 工作流整体结构改了;
- 原来能跑通的部分也被带坏了;
- 最后错误反而更大。
所以我现在特别希望平台后面能加上:
- 节点保存;
- 局部回撤;
- 历史版本对比;
- 一键恢复到上一步。
因为工作流一旦复杂起来,没有回撤和局部保存,调试成本会非常高。
4. 提示词边界一旦不清,结果就很容易发散
这个问题和前面三个不一样,它更偏使用层,但我觉得同样很核心。
现在 Agent 的分析结果很多时候还是高度依赖提示词。如果角色、任务、分析逻辑、输出格式没有写清楚,结果就很容易发散。
而且这里还有一个很现实的问题:
AI 的结果不像规则类工作流那样天然确定,也不像多因子结果那样天然可量化。
规则对就是对,错就是错;
因子值能看 IC、能看回测;
但 Agent 输出很多时候是一段“看起来合理”的结论,这种东西到底有多可靠,其实并不容易衡量。
所以我现在的做法会更偏保守:
- 尽量把提示词边界写清;
- 尽量让输出结构化;
- 尽量不要一开始就让它处理太宽泛的问题。
但从平台角度来说,如果后面能进一步强化结构化输出模板,或者做一些结果约束,我觉得会对使用体验帮助很大。
七、这周我真正的收获,不是“跑通了”,而是“想明白了一点”
如果只看表面,这周像是在学习一些新概念:
RAG、MCP、skill、多智能体、交易节点。
但对我自己来说,真正有价值的不是记住了这些名词,而是开始把它们放到同一条链路里理解:
- RAG 是让它别闭门造车;
- MCP 是让多个智能体别打架;
- skill 是把能力留下来,而不是每次重讲一遍;
- 提示词不是包装,而是在定边界;
- 主智能体不是为了显得高级,而是为了统一收口和做决策。
我现在越来越觉得,交易场景里的 Agent,最关键的不是它会不会说很多,而是:
它最后给出的东西,你能不能接着用。
如果只能聊得热闹,但没法沉淀成稳定流程,那意义其实有限。
但如果它能慢慢把分析、分工、汇总、风控这些事情接起来,那这个方向就值得继续做。
八、我接下来准备怎么继续
如果接下来继续沿着这个方向学,我自己大概会这样往下走:
- 先把单智能体版本继续打磨稳一点;
- 再慢慢把趋势、量价、波动率这些逻辑拆成不同子智能体;
- 把已经比较稳定的分析过程沉淀成 skill;
- 尽量让输出变得更结构化,方便后面复盘;
- 继续先在模拟环境里折腾,不急着往实盘推。
我现在其实挺认同一个节奏的:
先把它当成研究助手,再慢慢看它有没有资格成为交易助手。
九、小结
这周让我最明确的一点是:
PandaAI 的 Agent 交易智能体,不只是把 AI 问答搬进工作流,而是在尝试把“角色、能力、协作、决策、执行”拼成一个系统。
它和规则流、多因子工作流,不是替代关系,更像是不同层次的能力:
- 规则流负责确定性;
- 多因子工作流负责研究和验证;
- 多智能体工作流负责组织这些能力,形成更像真实交易决策的链路。
当然,现在这个方向还远远没有到“已经非常成熟”的程度。模型稳定性、提示词边界、结果验证、算力消耗、工作流回撤这些地方,都还有不少可以继续打磨的空间。
但至少到第 6 周,我自己的感觉已经和一开始不太一样了。
以前我会把智能体看成一个“更会聊天的工具”;
现在我会更愿意把它理解成:
一个正在慢慢成型的研究与交易流程组织器。
这也是我接下来最想继续折腾下去的地方。
