上一篇文章我们对单品种时序策略建模的整体流程做了介绍。从这篇文章开始,我们逐一对每个步骤进行较为细致的探讨,看看如何从最底层构建完整的时序模型框架。
一般来说,在机器学习的各个环节中,数据的重要性大于特征,特征的重要性大于模型。所谓"Garbage In, Garbage Out",数据的好坏决定了模型预测的上限。这一篇我们细致探讨一下数据处理中的一些常见操作。
一 k线合成
以期货为例,我们看到的所有的行情数据都来源于交易所的tick级切片数据,为500毫秒对盘口报价的一个切片。通常包含的数据有:时间戳、最新价、最高价、最低价、成交量、成交额、持仓量、买一价、买一量、卖一价、卖一量。通常还可以购买到二档至五档的买卖价、买卖量。
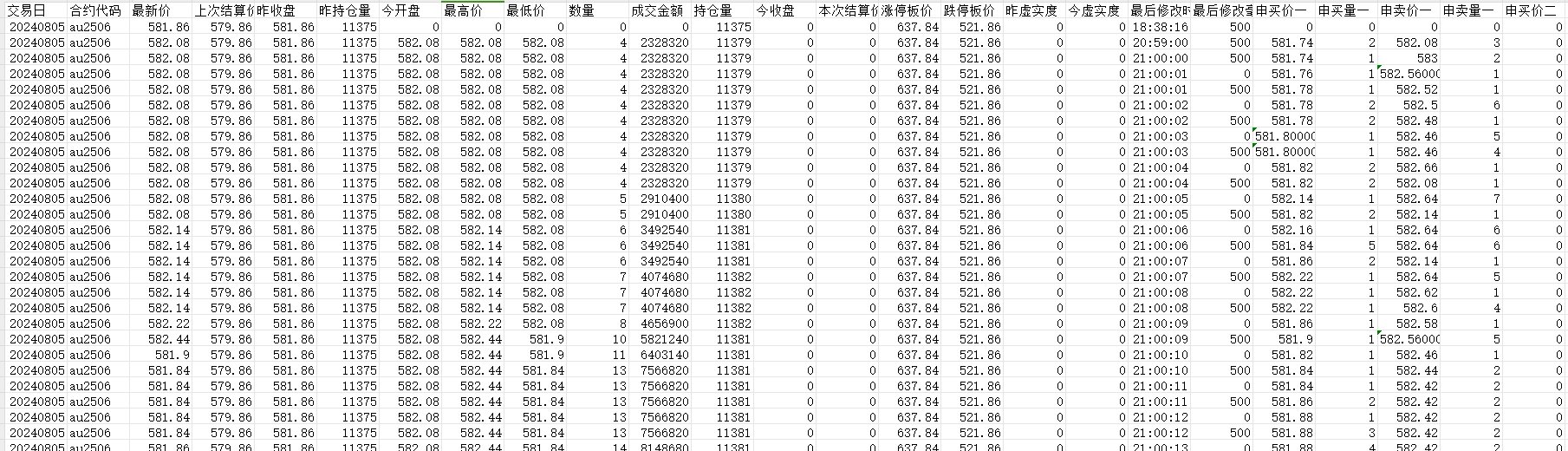
交易所本身并不发布k线数据,我们在各个软件上看到的k线实际上是各家数据商自己接收并处理,然后用软件可视化展示的。由于处理方式不同,我们从不同数据商那里拿到的k线可能会略有不同。比如一根k线的时间戳是用起始时间还是用结束时间。
常见的k线有1分钟、3分钟、5分钟、15分钟、1小时、1天、1周、1月。大家在同一尺度上做策略拥挤度会比较高,如果我们根据自己的交易频率选取合适的k线间隔,往往会有不一样的效果。
例如,我们想看看9分钟的k线什么样,可以这样做:
def create_datetime_index(self, df: pd.DataFrame) -> pd.DataFrame:
"""
创建完整的datetime索引
Args:
df: 原始数据DataFrame
Returns:
带有datetime索引的DataFrame
"""
df = df.copy()
# 创建完整的datetime
df['datetime'] = pd.to_datetime(df['date'] + ' ' + df['UpdateTime'].dt.strftime('%H:%M:%S'))
# 设置datetime为索引
df = df.set_index('datetime')
return df
# 创建datetime索引
df = create_datetime_index(df)
# 重采样生成K线
kline_data = df.resample("9min").agg({
'LastPrice': ['first', 'max', 'min', 'last'], # open, high, low, close
'Volume': 'sum', # volume
'Turnover': 'sum', # amount
'OpenInterest': 'last', # openint
'return': 'sum'
})
# 展平多级列名
kline_data.columns = ['open', 'high', 'low', 'close', 'volume', 'amount', 'openint', 'return']
# 重置索引
kline_data = kline_data.reset_index()
首先获取数据后要进行时间处理。对于每个tick数据打上对应的时间标签。要注意对于期货市场夜盘行情数据标记为下一个交易日,需要对日历日做处理。对于时间上的聚合python可以先将时间列转换为 datetime 对象,并设为索引,然后直接调用resample函数。LastPrice处理为高开低收,当前时间段对应的成交量、持仓量、成交额等加总或取最大值成为当前k线对应的值。
二 复权处理
期货市场通常选取主力合约交易,存在判断主力合约和移仓换月的问题。股票市场同样包含分红、拆股、配股等事件,会导致价格出现人为的“跳空”。
还是以期货为例,我们根据每个交易日的成交量或持仓量判断,选取最大的作为主力合约,不同主力合约拼接行情之后,不连续的地方需要做复权处理。
def forward_adjustment(df):
"""
对数据做“主力价格前复权”处理。
df 格式必须包含:
datetime, symbol, close, open, high, low, vwap
"""
if df.empty:
return df
df = df.sort_values(by='datetime', ascending=False)
df['rollfactor'] = (df['symbol'].shift(1) != df['symbol']).astype(int)
df['nextopen'] = df['open'].shift(1).fillna(df['close'].iloc[0])
df['rollfactor'] = df['rollfactor'] * df['nextopen'] / df['close']
df['rollfactor'] = df['rollfactor'].replace(0,1)
df['rollfactor'] = df['rollfactor'].cumprod()
df[['open', 'high', 'low', 'close', 'vwap']] = df[['open', 'high', 'low', 'close', 'vwap']].mul(df['rollfactor'],axis=0).round(4)
df = df.drop(['rollfactor','nextopen'],axis=1)
df = df.sort_values(by='datetime', ascending=True)
return df
def backward_adjustment(df):
"""
对数据做“主力价格后复权”处理。
df 格式必须包含:
datetime, symbol, close, open, high, low, vwap
"""
if df.empty:
return df
df = df.sort_values(by='datetime', ascending=True)
df['rollfactor'] = (df['symbol'].shift(1) != df['symbol']).astype(int)
df['preclose'] = df['close'].shift(1).fillna(df['open'].iloc[0])
df['rollfactor'] = df['rollfactor'] * df['preclose'] / df['open']
df['rollfactor'] = df['rollfactor'].replace(0,1)
df['rollfactor'] = df['rollfactor'].cumprod()
df[['open', 'high', 'low', 'close', 'vwap']] = df[['open', 'high', 'low', 'close', 'vwap']].mul(df['rollfactor'],axis=0).round(2)
df = df.drop(['rollfactor','preclose'],axis=1)
return df
数据商一般提供有处理好的主力连续合约可直接使用。通常看盘软件喜欢用前复权数据,用于技术分析、形态识别、支撑压力位判断。好处是图表的连续性和当前价格的真实性,非常适合人工看图。量化回测通常使用后复权,用于计算收益率、评估资金曲线、模拟真实交易。好处是保留历史购买力逻辑,资金模拟准确,统一基准。
三 降噪处理
通常金融数据充满了微观结构噪声(如买卖价差跳动、高频随机波动)等,为了去除高频随机波动,保留低频趋势特征,需要对数据进行平滑处理。
平滑处理通常有这么几个方法:
3.1 均线处理
均线是时序策略中最常用的方法没有之一。通常可以用移动平均或指数移动平均。好处是简单,无未来函数。缺点是有一定滞后性。
df['ma_noise_free'] = df['close'].rolling(window=20).mean()
df['ema_noise_free'] = df['close'].ewm(span=20, adjust=False).mean()
3.2 滤波处理
滤波可以在降噪的同时,更好地保留突变点,减少滞后性。例如卡尔曼滤波。
from pykalman import KalmanFilter
kf = KalmanFilter(transition_matrices=[1], observation_matrices=[1])
smoothed_mean, _ = kf.filter(df['close'].values)
df['kalman_noise_free'] = smoothed_mean.flatten()
3.3 频域处理
频域处理将时间序列转换到频域,切除高频部分,再转回时间域。比如傅里叶变换。注意避免直接对整个数组处理而不做移位修正,否则会引入严重的未来函数。
def FFTSmooth(self, signal, low_pass_ratio=0.9):
"""
对收盘价进行傅里叶低通滤波
low_pass_ratio: 保留低频比例 (0~1)
"""
# 1. 读取数据
n = len(signal)
# 2. 傅里叶变换
fft_values = np.fft.fft(signal)
fft_freq = np.fft.fftfreq(n, d=1)
# 3. 低通滤波:只保留前 low_pass_ratio 的低频
cutoff = int(n * low_pass_ratio / 2) # 保留左右对称部分
fft_filtered = np.zeros_like(fft_values)
fft_filtered[:cutoff] = fft_values[:cutoff] # 低频部分保留
fft_filtered[-cutoff:] = fft_values[-cutoff:] # 对称低频部分保留
# 4. 逆傅里叶变换恢复信号
filtered_signal = np.fft.ifft(fft_filtered).real
return filtered_signal[-1]
平滑处理的时候需要考虑降噪的程度与交易的波段相匹配。如果把所有波动都滤掉了,剩下的就是一条直线,策略将无法交易。可以将降噪后的序列与原序列做相关性分析,或者观察策略在降噪前后的夏普比率变化。有时候可以动态调整参数,在波动大时降噪幅度变大,波动小时降噪幅度变小。
四 缺失值及重复值处理
在金融数据中,总是会因为各种各样的原因出现缺失值。因此对各种有问题的数据进行处理是数据清洗中的最基本流程。
我们需要整体的检查数据的情况,寻找是否有断点或缺失点。
import pandas as pd
# 查看统计摘要
df.describe()
# 重点关注:
# min/max: 是否有负数的价格?是否有大得离谱的成交量?
# mean/std: 标准差是否过大?
# 查看每列缺失数量
print(df.isnull().sum())
# 查看缺失比例 print(df.isnull().mean())
# 可视化缺失情况
import missingno as msno
msno.matrix(df)
对于有些缺失值需要进行填补,尤其是模型无法处理NaN的时候。例如用sklearn提供的方法进行中位数填充。
from sklearn.impute import SimpleImputer
def _fit_imputer(self, X: np.ndarray):
"""为树模型做简单缺失值填补(中位数),防止 NaN 进入 sklearn RF 报错。"""
self._imputer = SimpleImputer(strategy="median")
self._imputer.fit(X)
def _transform_impute(self, X: np.ndarray) -> np.ndarray:
if getattr(self, "_imputer", None) is None:
self._fit_imputer(X)
return self._imputer.transform(X)
# 缺失值填补器以训练集拟合
self._fit_imputer(tr_X)
tr_X_imp = self._transform_impute(tr_X)
va_X_imp = self._transform_impute(va_X)
对于金融时序数据,我们需要确保数据严格按时间正序排列,将数据进行排序 (Sorting)处理。然后检查是否有重复的时间戳(常见于多数据源合并时)。处理方式为保留最后一条或第一条(通常保留最后一条,代表最终确认值)。
五 异常值处理
异常值处理也是数据清洗中的基本步骤。首先,我们需要做统计异常值检测 (Statistical Outliers),使用统计学方法找出偏离正常分布太远的点。对于正态分布的数据,可以使用三倍标准差进行异常值检验。但金融数据很多尖峰肥尾,并不属于正态,使用分位数方法更为稳健。
Q1 = df['close'].quantile(0.25)
Q3 = df['close'].quantile(0.75)
IQR = Q3 - Q1
# 定义异常值边界
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['close'] < lower_bound) | (df['close'] > upper_bound)]
找到异常值之后,如何处理也很有讲究。不能笼统的一删了之,需要检查异常的情况是否合理,视具体情况对不同场景下的异常值分别做出处理。
例如有些异常值有明显的逻辑问题,比如价格或成交量为负,高开低收的逻辑错误等待,可以直接进行剔除。
def clean_financial_data(df):
# 1. 类型转换
df['date'] = pd.to_datetime(df['date'])
cols = ['open', 'high', 'low', 'close', 'volume']
df[cols] = df[cols].apply(pd.to_numeric, errors='coerce')
# 2. 排序去重
df = df.sort_values('date').drop_duplicates(subset='date', keep='last')
# 3. 逻辑检查与修正
df = df[df['volume'] >= 0] # 删除负成交量
df = df[df['close'] > 0] # 删除零或负价格
# 修复 OHLC 逻辑
df['high'] = df[['open', 'high', 'low', 'close']].max(axis=1)
df['low'] = df[['open', 'high', 'low', 'close']].min(axis=1)
# 4. 缺失值处理 (前向填充)
df[cols] = df[cols].fillna(method='ffill')
# 5. 再次检查是否还有缺失 (如果开头就是缺失,ffill 无效)
df = df.dropna()
return df
对于极端行情,比如闪崩、涨停/跌停板等,则属于正常行情数据,一定要保留!这是重要的风险特征。在实际交易当中,这种行情下模型信号只差一根k线结果会有极大的差别。
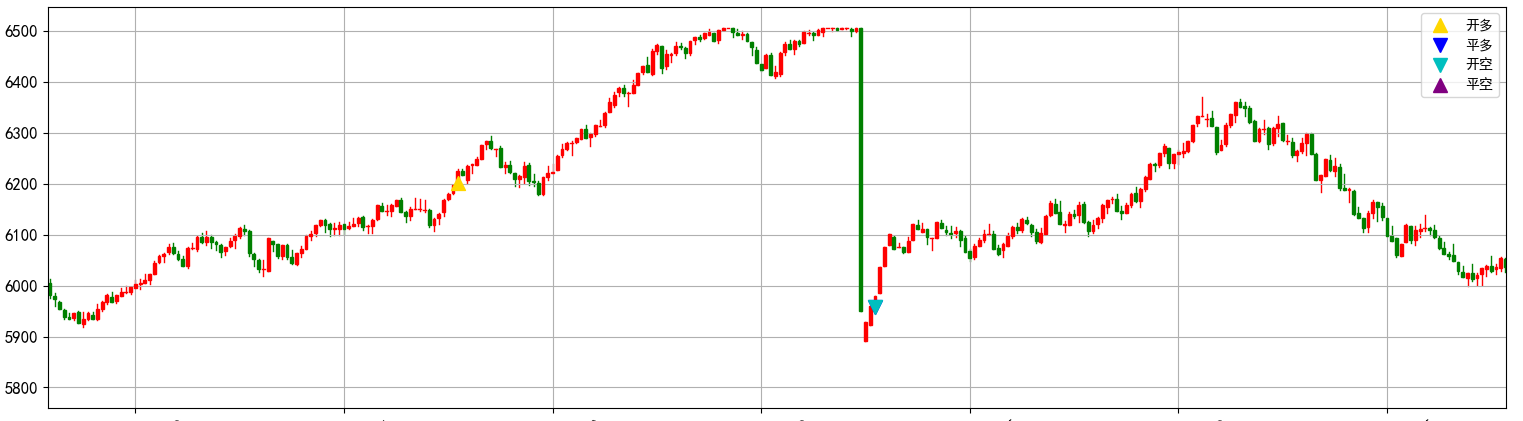
对于这样的行情数据,我们需要对其做出标记。可以使用 Winsorization (缩尾) 限制其影响范围,但不能删除。跳空行情绝对不要平滑掉。跳空包含了隔夜信息,是实盘必须面对的风险。
# 构造跳空特征
df['gap_pct'] = (df['open'] - df['close'].shift(1)) / df['close'].shift(1)
df['is_gap_up'] = (df['gap_pct'] > 0.02).astype(int) # 是否大幅高开
df['is_gap_down'] = (df['gap_pct'] < -0.02).astype(int) # 是否大幅低开
对于量化交易,宁可错过(剔除可疑数据),不可做错(使用错误数据训练),但对于真实的极端行情,必须保留以训练模型的风控能力。
六 数据总体检查
最后我们将整个数据处理流程总结一下。在开始建模前,检查以下问题:
- 时间索引是否连续且唯一?
- 复权是否已完成?
- OHLC 逻辑是否自洽(High >= Low)?
- 异常值是否已识别并合理处理?
- 是否避免了未来函数(全部使用了 shift 或 rolling)?
- 处理方式是否基于滚动窗口而非全局统计?
完成以上步骤后,才能得到干净、可用、能反映真实市场逻辑的数据。为后续的特征工程和模型构建打下坚实的基础。