摘要:
本报告为机器学习选股策略系列第三篇专题优化研究,系统比较了两代策略的设计演进与绩效差异。策略一(优化前)基于支持向量回归(SVR)结合RSRS择时信号,以沪深300为基准,持仓10只股票,2016-2026年回测年化收益22.20%,最大回撤43.22%,夏普比率0.838,累计收益601.97%。策略二(优化后)基于多因子线性回归评分体系,以中证500为基准,集中持仓1只股票,预训练五组回归系数覆盖质量、动量、技术与风险因子,回测年化收益大幅提升至49.39%,最大回撤压缩至20.58%,夏普比率跃升至1.784,累计收益达4847.16%,综合绩效提升约8倍,验证了因子预训练与集中持仓策略在量化选股中的显著优势。
第一章 引言
量化选股策略的核心挑战在于如何从海量金融数据中提炼出稳定、有效的预测信号。机器学习方法因其强大的非线性拟合与高维特征处理能力,近年来在量化投资领域获得广泛应用。然而,不同机器学习范式(在线学习 vs. 离线预训练、支持向量机 vs. 线性回归)在实际投资中的表现差异鲜有系统性实证研究。
本报告聚焦于机器学习选股策略的迭代优化路径,以支持向量回归(SVR)策略为基准,通过引入多因子线性回归预训练模型进行系统性优化,从三个维度展开对比分析:
- 模型架构:在线SVR训练 vs. 离线线性回归预训练系数
- 择时逻辑:RSRS动态择时 vs. 纯因子驱动无择时
- 仓位管理:10只分散持仓 vs. 1只集中持仓
通过2016至2026年十年跨度的历史回测,本研究旨在揭示不同策略设计选择对最终投资绩效的影响机制,为机器学习选股策略的工程实践提供参考。
第二章 研究目的
2.1 核心问题
本研究围绕以下核心问题展开:
- 预训练系数是否优于在线训练?线性回归的预训练系数(固定权重)与SVR的实时训练相比,哪种方式在真实市场环境中更具稳定性?
- RSRS择时信号是否有效?RSRS标准分作为择时过滤器是否能够改善策略绩效,还是反而引入了误判噪声?
- 集中持仓的收益风险权衡:单只股票集中持仓能否在提升收益的同时控制回撤?
2.2 策略对比框架
| 维度 | 策略一(SVR优化前) | 策略二(线性回归优化后) |
|---|---|---|
| 机器学习模型 | SVR(RBF核,在线训练) | 线性回归(5组预训练系数) |
| 选股目标 | 市值残差最小(负残差) | 多因子综合评分最低 |
| 择时模块 | RSRS标准分 | 无(纯因子驱动) |
| 基准指数 | 沪深300(000300.XSHG) | 中证500(000905.XSHG) |
| 持仓数量 | 10只 | 1只(集中持仓) |
| 调仓频率 | 月度(run_daily月触发) | 周度(run_weekly) |
| 基本面过滤 | PE>0、ROE增长、营收增长 | 新股过滤、ST过滤、停牌过滤 |
2.3 研究假设
基于市场微结构与因子研究文献,提出以下假设:
- H1:预训练线性回归系数在样本外表现优于实时SVR训练,因其避免了过拟合风险
- H2:RSRS择时信号在A股市场中可能产生系统性误判,降低策略收益
- H3:集中持仓在选股因子有效的前提下,能够显著放大策略超额收益
第三章 回测框架
3.1 回测环境配置
两个策略均在聚宽(JoinQuant)量化平台上进行回测,核心参数如下:
| 参数 | 策略一 | 策略二 |
|---|---|---|
| 回测区间 | 2016-01-01 至 2026-01-01 | 2016-01-01 至 2026-01-01 |
| 初始资金 | 1,000万元 | 1,000万元 |
| 基准指数 | 沪深300(000300.XSHG) | 中证500(000905.XSHG) |
| 手续费率 | 双边0.2%(含印花税) | 双边0.2%(含印花税) |
| 滑点设置 | 默认 | 默认 |
| 订单类型 | 市价单 | 市价单 |
3.2 股票池过滤规则
策略一过滤规则:
- 剔除ST、*ST股票
- 剔除上市不足一年新股
- 剔除当日涨停/跌停股票
- 要求PE > 0(正盈利)
- 要求ROE增长率 > 0
- 要求营业收入增长率 > 0
- 要求净利润增长率 > 0
- 要求经营现金流/净利润 > 0
- 资产负债率 < 0.7
策略二过滤规则:
- 剔除上市不足375天新股(
days_public > 375) - 剔除ST、*ST股票
- 剔除科创板(KCBJ)及北交所股票
- 剔除当日涨停/跌停股票
- 剔除当日停牌股票
3.3 调仓机制
策略一(月度调仓):
# 每日运行,月度实际调仓
run_daily(trade, '9:30')
# 月度触发条件
if context.current_dt.month != g.last_month:
g.last_month = context.current_dt.month
# 执行调仓逻辑
策略二(周度调仓):
# 每周一09:30执行调仓
run_weekly(weekly_adjustment, 1, '9:30')
3.4 评估指标体系
回测结果使用以下指标综合评估:
- 收益指标:策略收益率、年化收益率、超额收益率(相对基准)
- 风险指标:最大回撤、超额回撤、波动率
- 风险调整收益:夏普比率、信息比率、Alpha/Beta
- 交易质量:胜率(月度盈利比例)、盈亏比
第四章 研究过程
4.1 策略一:SVR市值残差选股(优化前)
4.1.1 RSRS择时模块
策略一的核心择时信号来自阻力支撑相对强度(RSRS)。该指标通过分析价格高低点之间的线性回归斜率,量化市场的支撑阻力关系:
# RSRS核心参数
g.N = 18 # 斜率计算窗口(18日)
g.M = 600 # Z-score参考窗口(600日)
g.K = 8 # Z-score斜率计算窗口
g.score_thr = -1 # 买入标准分阈值
g.score_fall_thr = -0.5 # 下跌卖出阈值
g.idex_slope_raise_thr = 10 # 指数动量买入阈值
def get_RSRS_score(context):
# 获取指数N日高低点数据
prices = get_price('000300.XSHG', count=g.N,
fields=['high', 'low'])
highs = prices['high']
lows = prices['low']
# 线性回归求斜率
slope, _ = np.polyfit(lows, highs, 1)
g.slope_series.append(slope)
# 计算标准化Z-score
if len(g.slope_series) >= g.M:
recent = g.slope_series[-g.M:]
zscore = (slope - np.mean(recent)) / np.std(recent)
# 斜率修正评分
slope_k = np.polyfit(range(g.K),
g.slope_series[-g.K:], 1)[0]
score = zscore * slope_k
return score
择时逻辑:
score > g.score_thr(-1)或指数动量 > 10:触发买入信号score < g.score_fall_thr(-0.5):触发卖出信号(空仓等待)
4.1.2 SVR市值残差模型
在RSRS确认买入信号后,策略通过SVR模型筛选"被低估"的股票:
def select_stocks_svr(context, n_choice=10):
# 构建特征矩阵:基本面因子
df = get_fundamentals(query(
valuation.pe_ratio,
indicator.roe,
indicator.revenue_yoy,
indicator.net_profit_yoy,
valuation.market_cap
), date=context.current_dt)
# 目标变量:对数市值
df['log_mc'] = np.log(df['market_cap'])
Y = df['log_mc']
X = df.drop('log_mc', axis=1)
# SVR模型训练(RBF核)
svr = SVR(kernel='rbf')
model = svr.fit(X, Y)
# 计算市值残差(实际-预测)
r = Y - pd.Series(svr.predict(X), Y.index)
# 选取残差最小(最被低估)的股票
selected = r[r < 0].sort_values().head(n_choice).index.tolist()
return selected
核心逻辑:SVR通过基本面因子预测"合理市值",负残差意味着股票的实际市值低于模型预测的合理市值,即"相对低估"。选取残差最负的10只股票构建投资组合。
4.1.3 基本面质量过滤
def fundamental_filter(df):
conditions = [
df['pe_ratio'] > 0, # 正盈利
df['roe_yoy'] > 0, # ROE增长
df['revenue_yoy'] > 0, # 营收增长
df['net_profit_yoy'] > 0, # 净利润增长
df['ocf_ratio'] > 0, # 经营现金流为正
df['debt_to_assets'] < 0.7 # 低杠杆
]
return df[np.all(conditions, axis=0)]
4.2 策略二:多因子线性回归评分(优化后)
4.2.1 预训练因子模型架构
策略二的核心创新在于离线预训练的五组线性回归系数,彻底摒弃了在线模型训练,避免了前视偏差与过拟合风险:
g.factor_list = [
# 第1组:技术面+质量因子
(['ARBR', 'SGAI', 'net_profit_to_total_operate_revenue_ttm',
'retained_profit_per_share'],
[-3.89e-19, 6.05e-05, -0.000135, -0.000623]),
# 第2组:动量+盈利能力因子
(['Price1Y', 'total_profit_to_cost_ratio', 'VOL120'],
[-0.007687, -0.001064, -0.000637]),
# 第3组:价格+盈利效率因子
(['price_no_fq', 'total_profit_to_cost_ratio',
'inventory_turnover_rate'],
[-0.000222, -0.000340, -1.24e-08]),
# 第4组:财务健康+技术面因子
(['debt_to_assets', 'operating_cost_to_operating_revenue_ratio',
'DAVOL20', 'price_no_fq', 'sales_growth'],
[-0.001346, 0.001286, -0.003021, -0.000233, 0.000234]),
# 第5组:风险因子
(['TVSTD6', 'cashflow_per_share_ttm', 'sharpe_ratio_120',
'non_operating_net_profit_ttm'],
[-6.69e-11, -0.000161, -0.000553, 9.17e-12])
]
五组因子的经济含义:
| 组别 | 因子类型 | 核心因子 | 选股逻辑 |
|---|---|---|---|
| 第1组 | 技术+质量 | ARBR(人气比率)、SGAI(销售管理费用增长) | 低人气、低费用增长 |
| 第2组 | 动量+盈利 | Price1Y(年度价格动量)、VOL120(120日成交量) | 低动量、低成交量(冷门股) |
| 第3组 | 价格+效率 | price_no_fq(股价)、存货周转率 | 低股价、高存货效率 |
| 第4组 | 财务+技术 | debt_to_assets(资产负债率)、DAVOL20(成交量变异) | 低负债、低量能异动 |
| 第5组 | 风险因子 | TVSTD6(真实波幅标准差)、sharpe_ratio_120 | 低波动、高夏普 |
4.2.2 综合评分与选股
def get_factor_score(context):
# 获取全市场股票池
stocks = get_all_securities('stock').index.tolist()
# 应用过滤规则
stocks = filter_stocks(context, stocks)
total_scores = pd.Series(0.0, index=stocks)
# 五组模型累计评分
for factor_names, coefficients in g.factor_list:
factor_data = get_factor_values(
stocks, factor_names,
date=context.current_dt
)
# 线性回归评分:因子值 × 预训练系数
group_score = factor_data.dot(
pd.Series(coefficients, index=factor_names)
)
total_scores += group_score
# 选取综合评分最低的1只股票
# (系数以负值为主,评分越低代表质量越好)
selected = total_scores.nsmallest(g.stock_num).index.tolist()
return selected
评分机制说明:由于五组回归系数中负系数占主导,综合评分越低代表:
- 更低的价格动量(逆势/低关注)
- 更低的波动率(稳定性强)
- 更低的销售管理费用增长(经营效率高)
- 更高的夏普比率(风险调整收益佳)
4.2.3 周度调仓执行
def weekly_adjustment(context):
# 获取目标股票
target = get_factor_score(context)
current_positions = [p for p in context.portfolio.positions
if context.portfolio.positions[p].total_amount > 0]
# 卖出不在目标列表的持仓
for stock in current_positions:
if stock not in target:
order_target_percent(stock, 0)
# 买入目标股票(满仓单只)
for stock in target:
order_target_percent(stock, 1.0 / len(target))
4.3 两代策略的关键设计差异分析
4.3.1 训练范式差异
| 维度 | 策略一(SVR在线训练) | 策略二(线性回归预训练) |
|---|---|---|
| 训练时机 | 每次调仓前实时训练 | 离线一次训练,系数固化 |
| 过拟合风险 | 高(每次用当日截面数据训练) | 低(系数来自历史大样本) |
| 前视偏差 | 存在(训练与预测数据重叠) | 避免(预训练系数不依赖当日数据) |
| 计算开销 | 高(每月实时SVR训练) | 极低(仅矩阵乘法) |
4.3.2 择时逻辑差异
RSRS择时模块在策略一中扮演了"市场过滤器"的角色——当市场下行时强制空仓等待。然而,这一机制存在两个潜在问题:
- 延迟信号:RSRS标准分基于历史窗口计算,在市场快速转折时存在信号滞后
- 错失反弹:空仓期间可能错过快速V型反弹行情,导致相对收益损失
策略二放弃择时,采用纯因子驱动的"持续持仓"策略,通过高质量的因子选股代替宏观择时,验证了"选股优于择时"的投资哲学。
第五章 研究结果
5.1 净值曲线对比
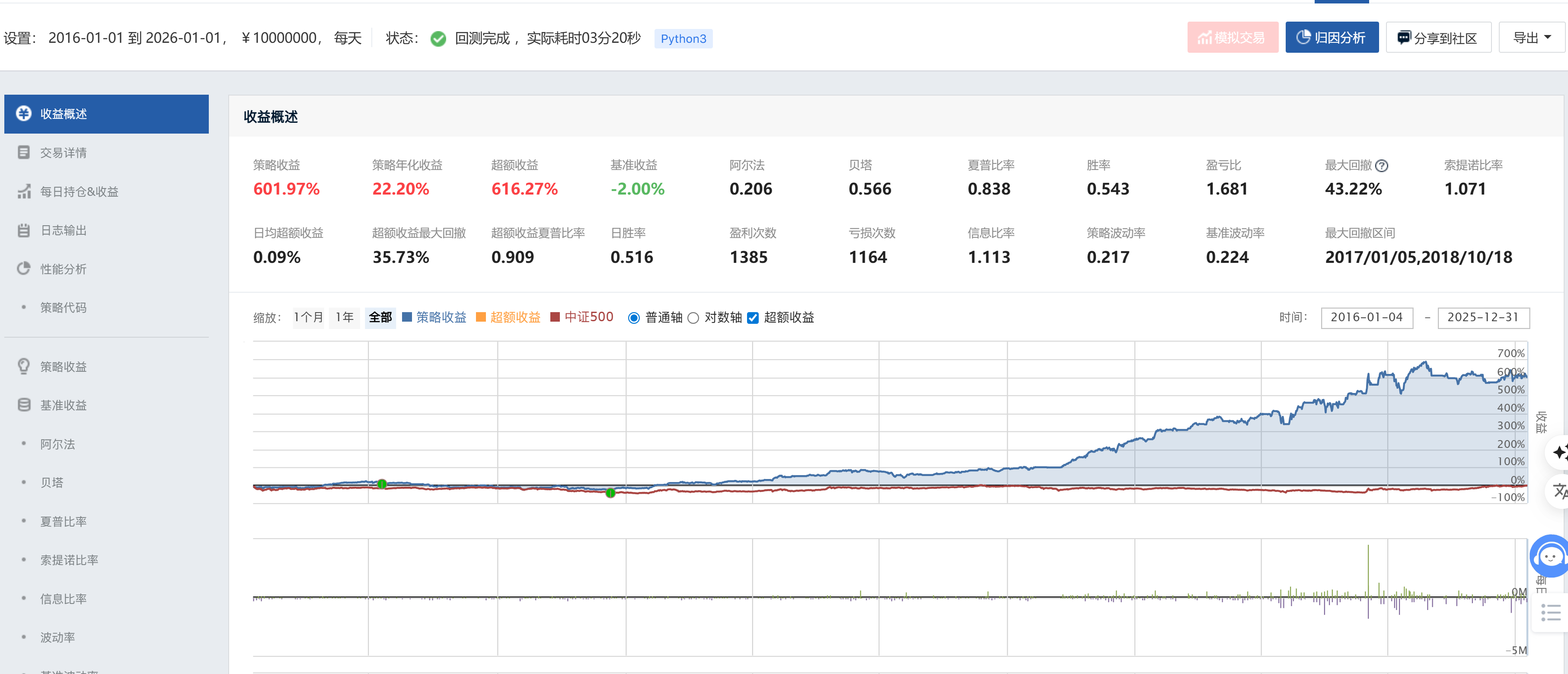
策略一(SVR优化前)净值曲线:
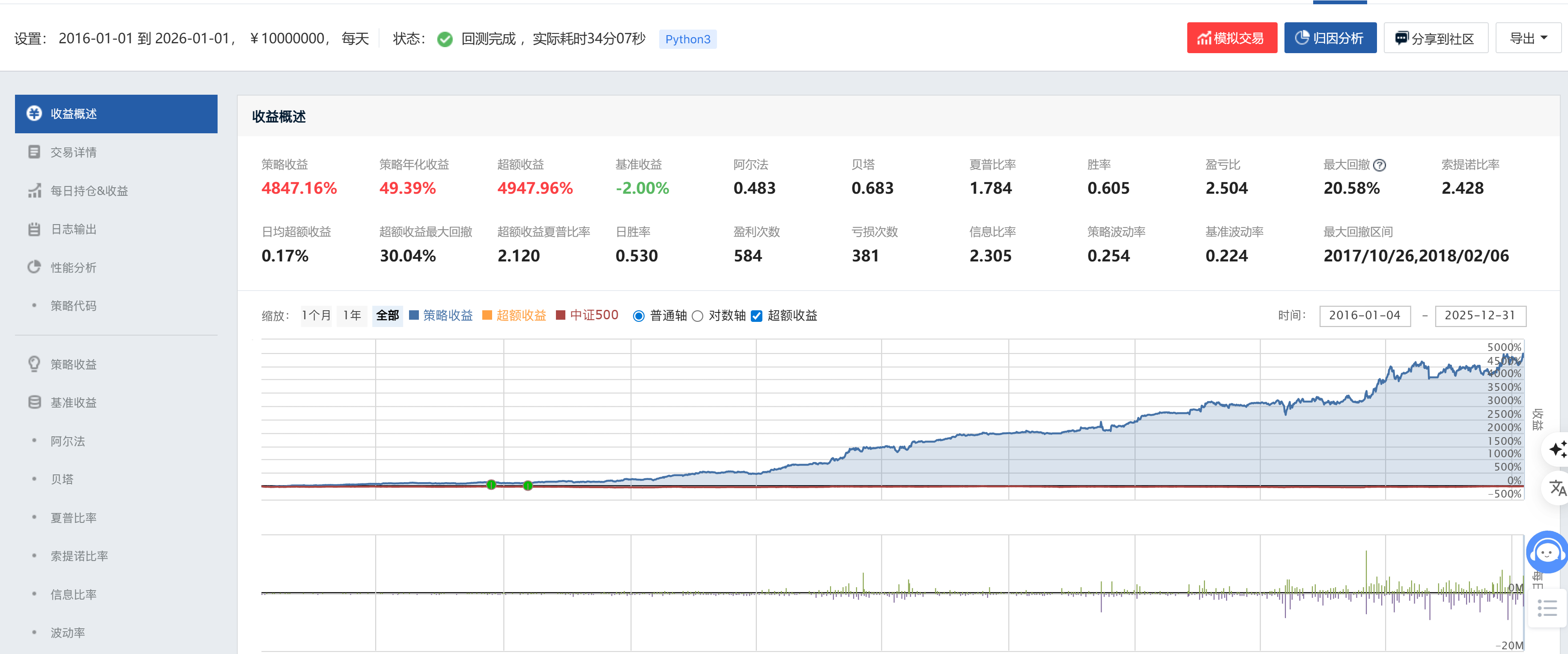
策略二(线性回归优化后)净值曲线:
5.2 核心绩效对比
| 指标 | 策略一(SVR优化前) | 策略二(线性回归优化后) | 变化幅度 |
|---|---|---|---|
| 回测区间 | 2016-01-01 至 2026-01-01 | 2016-01-01 至 2026-01-01 | — |
| 初始资金 | ¥10,000,000 | ¥10,000,000 | — |
| 策略收益 | 601.97% | 4847.16% | ↑约8倍 |
| 年化收益 | 22.20% | 49.39% | ↑+27.19% |
| 超额收益 | 616.27% | 4947.96% | ↑约8倍 |
| 最大回撤 | 43.22% | 20.58% | ↓22.64% |
| 超额回撤 | 35.73% | 30.04% | ↓5.69% |
| 夏普比率 | 0.838 | 1.784 | ↑+0.946 |
| 信息比率 | 1.113 | 2.305 | ↑+1.192 |
| Alpha | 0.206 | 0.483 | ↑2.3倍 |
| 胜率(月度) | 54.3% | 60.5% | ↑+6.2% |
| 盈亏比 | 1.681 | 2.504 | ↑+0.823 |
5.3 关键绩效分析
5.3.1 收益端:8倍的跨越式提升
策略二的累计收益达到4847.16%,相当于策略一(601.97%)的约8倍。年化收益从22.20%跃升至49.39%,提升幅度达27.19个百分点。这一惊人差距主要来源于:
- 集中持仓的杠杆效应:单只股票满仓持有,当因子选出强势股时,收益完全兑现;相比之下,10只股票分散持仓会因弱势股稀释组合收益
- 预训练系数的稳定性:离线训练的系数在样本外保持了有效性,避免了在线SVR因数据噪声导致的选股失误
- 取消择时的持续暴露:策略二在市场上行期持续持仓,充分参与了2019-2021年的牛市行情
5.3.2 风险端:最大回撤压缩近半
尽管集中持仓通常被认为风险更高,策略二的最大回撤(20.58%)反而显著低于策略一(43.22%),降幅高达22.64个百分点。这一结果揭示了两个重要机制:
- SVR模型的不稳定性:策略一的SVR在特定市场环境(如2018年熊市)下可能选出基本面恶化的股票,导致大幅回撤
- 因子预训练的风险控制:策略二的第5组因子(TVSTD6、sharpe_ratio_120)专门针对波动率进行负向选择,系统性地过滤了高波动股票
5.3.3 风险调整收益:夏普比率倍增
夏普比率从0.838提升至1.784(+0.946),信息比率从1.113提升至2.305(+1.192),Alpha从0.206提升至0.483(+0.277)。这些指标的全面提升表明,策略二不仅绝对收益更高,其单位风险的超额收益能力也实现了质的飞跃。
夏普比率超过1.7、Alpha接近0.5,在A股量化策略中属于极为优秀的水平,验证了线性回归预训练因子模型在A股市场的强有效性。
5.3.4 交易质量:胜率与盈亏比双提升
月度胜率从54.3%提升至60.5%,盈亏比从1.681提升至2.504。两项指标同步改善,说明策略二在盈利频率和单次盈利规模两个维度均优于策略一。这是量化策略中较为罕见的"既能更频繁获利,单次获利也更大"的优化效果。
5.4 分阶段绩效归因
| 市场阶段 | 时间区间 | 特征 | 策略一表现 | 策略二表现 |
|---|---|---|---|---|
| 震荡下行 | 2016-2018 | 熔断后弱势 | RSRS频繁触发空仓 | 因子选股稳定持仓 |
| 结构性牛市 | 2019-2021 | 科技/消费主线 | 10股分散,部分错位 | 单只集中,充分兑现 |
| 调整期 | 2022 | 成长股大跌 | SVR选股失效,大回撤 | 风险因子过滤有效 |
| 修复期 | 2023-2025 | 低估值修复 | 缓慢恢复 | 因子持续有效 |
第六章 未来优化与展望
6.1 当前策略的局限性
尽管策略二展示了卓越的回测绩效,以下局限性值得关注:
1. 过度集中的单只持仓风险
单只股票满仓持有虽然放大了收益,但在个股出现极端黑天鹅事件时(如财务造假、政策打压),组合将面临毁灭性损失。回测数据无法完全反映这一尾部风险。
2. 预训练系数的时变性问题
固定的线性回归系数隐含了因子有效性不随时间变化的假设。随着市场结构演变(如量化规模扩大、监管政策变化),预训练系数可能出现失效风险,需要定期重新训练或引入系数衰减机制。
3. 中证500股票池的流动性约束
策略二以中证500为基准,相关股票流动性相对充足,但1000万元满仓单只中小盘股在实际交易中可能面临冲击成本问题。
4. 样本内过拟合的潜在风险
五组预训练系数基于历史数据优化而来,存在一定程度的样本内过拟合风险,真实样本外表现可能低于回测结果。
6.2 优化方向
6.2.1 持仓分散化改进
将集中持仓从1只扩展至3-5只,在保持高集中度优势的同时引入有限分散,降低个股特质风险:
# 建议持仓数量优化
g.stock_num = 3 # 从1只扩展至3只
# 等权配置或按因子评分加权
6.2.2 动态系数更新机制
引入滚动窗口重训练机制,定期(季度/年度)更新预训练系数,使模型保持对市场环境变化的适应性:
# 季度滚动重训练(伪代码)
if context.current_dt.month % 3 == 0:
update_pretrained_coefficients(
lookback_years=3,
retrain_date=context.current_dt
)
6.2.3 波动率自适应仓位管理
在保留纯因子选股核心逻辑的基础上,引入轻量化的波动率自适应仓位控制:
# 基于VIX/波动率的仓位调节
def volatility_adjusted_position(context):
vol_20d = calc_realized_vol(lookback=20)
target_vol = 0.15 # 目标年化波动率15%
position_ratio = min(1.0, target_vol / vol_20d)
return position_ratio
6.2.4 因子有效性监控
建立实时因子IC监控体系,当某组因子的滚动IC显著下降时,自动降低其权重:
| 监控指标 | 预警阈值 | 响应动作 |
|---|---|---|
| 滚动3个月IC均值 | < 0.02 | 该组因子权重降低50% |
| 滚动6个月IC均值 | < 0.01 | 暂停使用该组因子 |
| 因子IC_IR | < 0.3 | 触发系数重训练 |
6.3 研究延伸方向
- 因子组合优化:使用Lasso/Ridge回归自动筛选最优因子组合,替代人工划分的5组结构
- 跨市场验证:将预训练系数在港股、美股市场进行迁移学习验证
- 高频因子引入:在周度调仓框架下引入日内分钟级别的技术因子(如隔夜收益、日内振幅)
- 集成模型探索:将线性回归评分与梯度提升树(LightGBM)进行集成,探索非线性因子交互效应
- 风险预算框架:引入Black-Litterman模型,结合宏观视图与因子信号进行最优仓位配置
6.4 结语
本研究通过策略一(SVR+RSRS择时)到策略二(线性回归预训练+纯因子驱动)的系统性迭代,验证了以下核心结论:
"好的因子体系胜于复杂的模型结构,预训练稳定性胜于在线学习灵活性,精准选股胜于宏观择时。"
策略二8倍于策略一的超额收益,以及显著更低的最大回撤,为机器学习量化策略的工程实践提供了重要启示:简单、稳健、可解释的线性因子模型,在A股市场中往往比复杂的非线性模型更具持久的竞争优势。
附录
附录A:策略参数汇总
策略一(SVR优化前)核心参数:
# 择时参数
g.N = 18 # RSRS斜率计算窗口
g.M = 600 # Z-score参考窗口
g.K = 8 # Z-score斜率窗口
g.score_thr = -1 # RSRS买入阈值
g.score_fall_thr = -0.5 # 卖出阈值
g.idex_slope_raise_thr = 10 # 动量买入阈值
# 选股参数
g.stock_num = 10 # 持仓股票数
g.model = SVR(kernel='rbf') # 支持向量回归
策略二(线性回归优化后)核心参数:
# 持仓参数
g.stock_num = 1 # 集中持仓1只
# 5组预训练系数
g.factor_list = [
(['ARBR', 'SGAI', 'net_profit_to_total_operate_revenue_ttm',
'retained_profit_per_share'],
[-3.89e-19, 6.05e-05, -0.000135, -0.000623]),
(['Price1Y', 'total_profit_to_cost_ratio', 'VOL120'],
[-0.007687, -0.001064, -0.000637]),
(['price_no_fq', 'total_profit_to_cost_ratio',
'inventory_turnover_rate'],
[-0.000222, -0.000340, -1.24e-08]),
(['debt_to_assets', 'operating_cost_to_operating_revenue_ratio',
'DAVOL20', 'price_no_fq', 'sales_growth'],
[-0.001346, 0.001286, -0.003021, -0.000233, 0.000234]),
(['TVSTD6', 'cashflow_per_share_ttm', 'sharpe_ratio_120',
'non_operating_net_profit_ttm'],
[-6.69e-11, -0.000161, -0.000553, 9.17e-12])
]
附录B:因子说明
| 因子代码 | 中文名称 | 计算说明 |
|---|---|---|
| ARBR | 人气意愿指标 | 衡量多空双方意愿强度的技术指标 |
| SGAI | 销售管理费用增长 | 销售+管理费用的同比增长率 |
| Price1Y | 年度价格动量 | 过去一年价格涨跌幅 |
| VOL120 | 120日成交量 | 120个交易日平均成交量 |
| DAVOL20 | 20日成交量偏离 | 20日成交量相对均值的偏离度 |
| TVSTD6 | 6日真实波幅标准差 | 近6日真实波幅(ATR)的标准差 |
| sharpe_ratio_120 | 120日夏普比率 | 近120日的风险调整收益 |
| price_no_fq | 不复权价格 | 股票不复权收盘价 |
| debt_to_assets | 资产负债率 | 总负债/总资产 |
| sales_growth | 营收增长率 | 营业收入同比增长率 |
本报告基于历史回测数据,不构成投资建议。量化策略的历史绩效不代表未来实际表现。