当前市场上的量化策略常见的为多因子截面,主要应用于股票市场。而期货市场、数字货币等因标的数量的限制,不容易构造有效的截面,以单品种时序策略为主。比如技术指标等规则类策略,机器学习类策略较少。本篇我们探索用机器学习的方法为单品种时序策略建模,并逐步构建完整的量化策略。
根据机器学习的处理流程,可以按以下步骤来做:数据准备->标签标注->特征构建->模型构建->回测与上线几大步骤。
一 数据准备
以期货为例,我们可以从数据供应商那里下载行情数据,基本为不同时间间隔的k线。期货k线数据通常包含价格的高开低收,以及当前时间段对应的成交量、持仓量、成交额等等。
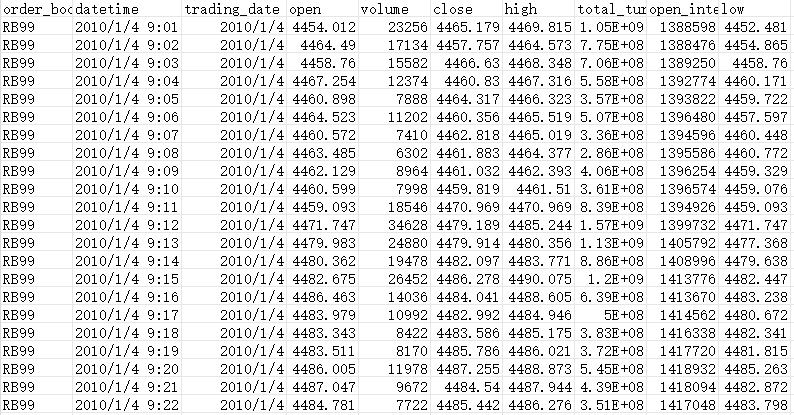
更为细化的tick数据还可以给出每500毫秒切片上一档至五档的买价、卖价、买量、卖量。对于交易频率要求高的用户可以选择购买。
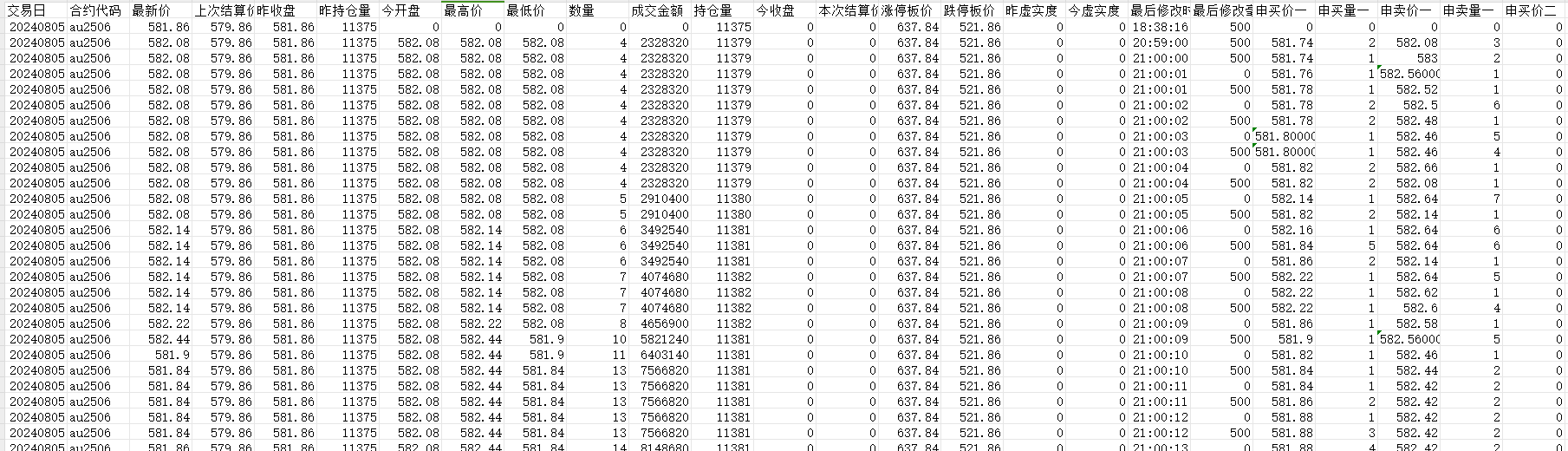
获取数据后首先进行时间处理。例如根据自己的交易频率选取合适的k线间隔,对于期货市场夜盘行情数据标记为下一个交易日,需要对日历日做处理。期货市场通常选取主力合约交易,存在判断主力合约和移仓换月的问题。需要根据每个交易日的成交量或持仓量判断,训练时并对不同主力合约拼接行情做复权处理。数据商一般提供有处理后的主力连续合约可直接使用。
数据训练前一般还需要对数据进行清洗,例如脏数据、极值、停牌/涨跌停、缺失值、错误成交量等等,这里不详细展开。待后续文章做具体的探讨。
二 标签标注
在建立模型之初,需要对预测目标做清楚的定义。例如预测未来收益率大小;或是预测上涨/下跌;对应不同的标签标注方式和任务类型。其主要预测类问题为分类问题和回归问题。
我们以最简单的分类任务为例,展示如何标注标签。对于单品种时序,预测分类可分为上涨和下跌。例如从当前开始,时间t后的价格与现在相比,上涨标注为1,下跌标注为0。从而形成最简单的二分类任务。
t时间的价格与当前相比等价于比较收益率大于0或小于0。有时候二分类的标签可以不平衡,例如t时间的收益率大于某个阈值标注为1。为了避免标签数量过于不平衡,可以先画出收益的分布,以某个比例定阈值。
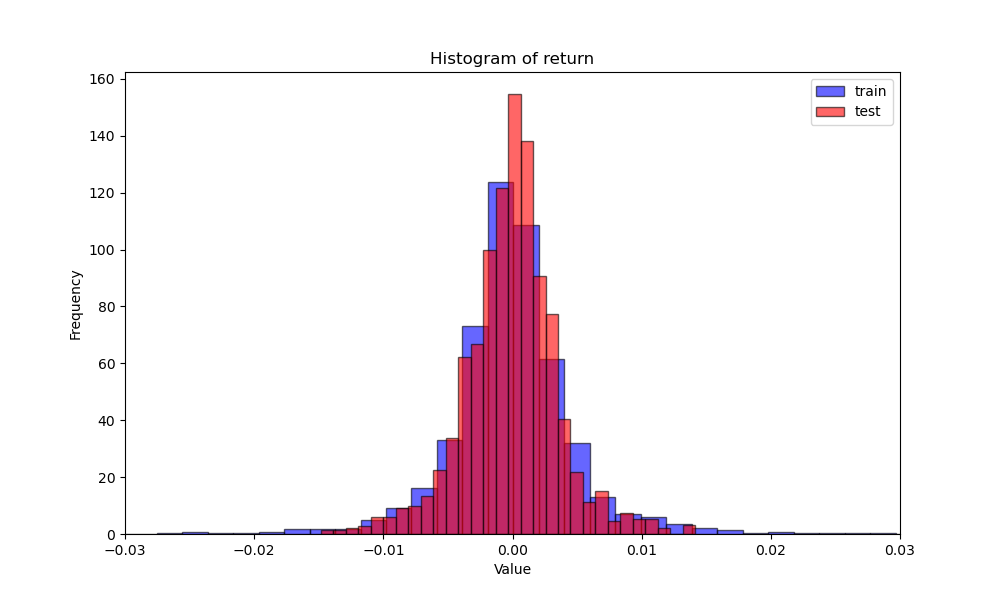
如上图的分布,我们希望标签为1的比例在三分之一,可以将图中右侧面积三分之一的地方切一刀,对应坐标大约是0.0025。同样的,也可以在左侧面积三分之一的地方切一刀,做成三分类模型。整个分布上段、中段、下段各三分之一。分别标注为1、0、-1。标签标注要与交易动作一致,如果是t+1执行,要把可交易时点对齐。
回归任务较为直接,可以把预测目标直接选为未来t时的收益率,注意直接计算收益率会存在噪音和极值,可以对收益进行平滑处理。
三 特征构建
特征是机器学习训练的原料,特征的好坏直接决定了模型预测的能力。特征通常包含以下几个类别:
- 价格/量价特征
- 滞后收益(lag returns)、动量、反转;
- 均线差、布林带宽、ATR、RSI、MACD;
- 成交量变化、量价背离、VWAP偏离。
- 波动与状态特征
- 滚动波动率、偏度峰度;
- regime/state(高波动/低波动、趋势/震荡);
- 时间特征(小时、星期几、月内效应)。
- 统计与信号处理
- 滚动z-score、分位数位置;
- 小波/频域特征(高级可选);
- 分形/Hurst(研究型特征)。
构建特征之后需要对特征做预处理,比如标准化/归一化,缺失值填充等等。并且根据特征对应的时间戳对数据进行拆分,一部分用于训练、一部分用于验证,最后留一部分用于测试。训练集、验证集、测试集比例可以设置为7:2:1。注意预处理所需参数只在训练数据拟合。
四 模型训练
在金融领域机器学习以判别式模型为主,其代表性的模型有决策树,SVM,逻辑回归,以及Ridge、Lasso等各式线性模型。Sklearn集成了大部分机器学习模型,封装好以统一的格式可供调用。这里以随机森林为例,简要展示树模型的调用过程。
在特征工程和测试集训练集划分完成后,我们需要定义随机森林模型。随机森林主要参数如下:
1,n_estimators:
- 含义:森林中决策树的数量。类似 “投票小组” 人数,人数太少易出错(欠拟合),太多则计算慢。
- 量化场景:若因子相关性高,需增加树的数量提升多样性(如 100-500 棵)。
- 调优:随数据量增大而增加,配合max_features避免过拟合。
2,max_depth:
- 含义:单棵树的最大层数,控制树的复杂度。层数深可能记住噪声(过拟合),浅则抓不到复杂规律。
- 量化场景:因子逻辑简单(如价量因子)时设为 5-10 层;因子复杂(如基本面 + 舆情)可设为 15-20 层。
3,max_features:
- 含义:每次分裂时随机选择的特征数(如auto表示√n_features)。类似 “每次考试随机抽题”,避免单因子垄断决策。
- 量化场景:因子数量多(如 200 + 因子)时,设为sqrt或log2,降低计算量。
4,min_samples_split:
- 含义:节点分裂所需的最小样本数。值越小,树越 “茂盛”(可能过拟合)。
- 量化场景:样本少(如 500 个股票)时设为 10-20;样本多(如 10 万条交易记录)可设为 50-100。
参数定义完成后对训练集进行fit,然后对测试集做出predict。
# 1. 获取特征
X = custom_feature_generator(X, y)
# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y
)
# 3. 定义并训练随机森林模型
rf = RandomForestClassifier(
n_estimators=200,
max_depth=6,
min_samples_split= 20,
min_samples_leaf= 10,
max_features= 'sqrt',
bootstrap= True,
random_state=42,
n_jobs=-1
)
rf.fit(X_train, y_train)
# 4. 使用 predict_proba 得到正类(1)的预测概率
proba_test = rf.predict_proba(X_test)[:, 1] # 只取 P(y=1)
proba_train = rf.predict_proba(X_train)[:, 1] # 只取 P(y=1)
模型预测完成后,我们需要对结果进行评价。常见的模型评估指标有:
- 回归任务
- MAE、RMSE、R²、IC(信息系数);
- 分类任务
- AUC、F1、Precision/Recall、Brier Score、ECE(Expected Calibration Error) ;等等
五 回测与上线
很多预测准确的模型并不一定能赚钱,还需要看交易指标。这就涉及到回测及交易层面的评估指标。
首先需要将预测结果转化为交易执行。例如涨跌二分类问题,预测上涨信号后以当前价格买入,预测下跌信号后以当前价格卖出。如果已有持仓时需要判断仓位与涨跌的情况,做出保留持仓(比如信号与当前仓位一致)和平仓(比如信号与当前仓位不一致)的判断。
回测时需要严格区分样本内与样本外数据。样本内数据参与训练,通常为训练集和验证集。样本外数据需要严格保持未参与任何调参,通常为测试集数据。需要对模型调参时,尽量避免反复在同一测试集上调参。并且需要查看参数的敏感性,即查看参数的变化对结果的影响是否剧烈,尽量在参数平原上选择参数。回测还需要考虑手续费、滑点、信号延迟等。可以对牛熊、震荡、高波动阶段分别评估。
交易评估指标通常有:
- 年化收益、夏普、Calmar;
- 最大回撤、回撤时长;
- 胜率、盈亏比、换手率;
- 扣除手续费与滑点后的净值曲线。
模型上线前需要检查的一些问题:比如随机切分数据是否会导致未来信息泄漏?计算技术指标是否使用了未来窗口(无意穿越)?是否低估了手续费滑点,回测过于乐观?标签和执行时点是否错位(看起来“神准”是否只是预测过去?)是否在测试集上反复调参,间接增加过拟合?是否特征过多、样本太少,过拟合严重,导致回测优秀,实盘完全失效?
六 整体流程实现
最后我们将整个流程用python简要实现如下,感兴趣的朋友可以在自己的电脑上进行测试。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from scipy.stats import spearmanr
# ============ 1) 参数区 ============
CSV_PATH = "data.csv" # 改成你的数据文件
HORIZON = 1 # 预测未来几根K线收益
TRAIN_RATIO = 0.7
VALID_RATIO = 0.15 # 剩余自动作为test
RANDOM_STATE = 42
# 随机森林参数(先用保守参数,避免过拟合)
RF_PARAMS = dict(
n_estimators=300,
max_depth=6,
min_samples_leaf=20,
max_features="sqrt",
random_state=RANDOM_STATE,
n_jobs=-1
)
# 策略参数
SIGNAL_THRESHOLD = 0.0005 # 预测收益绝对值超过阈值才开仓
COST_BPS = 3 # 单边交易成本(bps)
MAX_LEVERAGE = 1.0 # 最大仓位绝对值
# ============ 2) 读数据 ============
def load_data(path: str) -> pd.DataFrame:
df = pd.read_csv(path)
df["datetime"] = pd.to_datetime(df["datetime"])
df = df.sort_values("datetime").reset_index(drop=True)
needed = ["open", "high", "low", "close", "volume"]
for c in needed:
if c not in df.columns:
raise ValueError(f"缺少列: {c}")
return df
# ============ 3) 特征工程 ============
def make_features(df: pd.DataFrame) -> pd.DataFrame:
x = df.copy()
# 基础收益与波动
x["ret_1"] = x["close"].pct_change(1)
x["ret_5"] = x["close"].pct_change(5)
x["ret_10"] = x["close"].pct_change(10)
x["vol_5"] = x["ret_1"].rolling(5).std()
x["vol_20"] = x["ret_1"].rolling(20).std()
# 均线偏离
ma_5 = x["close"].rolling(5).mean()
ma_20 = x["close"].rolling(20).mean()
x["ma_gap_5"] = x["close"] / ma_5 - 1
x["ma_gap_20"] = x["close"] / ma_20 - 1
# 量能特征
x["vol_chg_1"] = x["volume"].pct_change(1)
x["vol_ma_5"] = x["volume"].rolling(5).mean()
x["vol_ratio_5"] = x["volume"] / x["vol_ma_5"]
# 振幅
x["hl_spread"] = (x["high"] - x["low"]) / x["close"]
return x
# ============ 4) 标签构建 ============
# 回归问题
def make_label(df: pd.DataFrame, h: int) -> pd.Series:
# 未来h期收益(回归标签)
y = df["close"].shift(-h) / df["close"] - 1
return y.rename("target")
# 分类问题
def make_binary_label(df: pd.DataFrame, h: int) -> pd.Series:
# 未来h期收益
fwd_ret = df["close"].shift(-h) / df["close"] - 1
# 涨=1,跌/平=0
y = (fwd_ret > 0).astype(int)
return y.rename("target")
# ============ 5) 时间切分 ============
def time_split(df: pd.DataFrame, train_ratio: float, valid_ratio: float):
n = len(df)
train_end = int(n * train_ratio)
valid_end = int(n * (train_ratio + valid_ratio))
train = df.iloc[:train_end].copy()
valid = df.iloc[train_end:valid_end].copy()
test = df.iloc[valid_end:].copy()
return train, valid, test
# ============ 6) 评价函数 ============
# 回归问题
def eval_regression(y_true, y_pred, name="set"):
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
mae = mean_absolute_error(y_true, y_pred)
r2 = r2_score(y_true, y_pred)
ic = spearmanr(y_true, y_pred).correlation # 信息系数(秩相关)
print(f"[{name}] RMSE={rmse:.6f} MAE={mae:.6f} R2={r2:.4f} SpearmanIC={ic:.4f}")
# 分类问题
def evaluate_cls(y_true: np.ndarray, y_score: np.ndarray, name="set", thr=0.5):
# Regressor输出分数,裁剪到[0,1]当作“上涨概率近似”
y_prob = np.clip(y_score, 0.0, 1.0)
y_pred = (y_prob >= thr).astype(int)
acc = accuracy_score(y_true, y_pred)
pre = precision_score(y_true, y_pred, zero_division=0)
rec = recall_score(y_true, y_pred, zero_division=0)
f1 = f1_score(y_true, y_pred, zero_division=0)
# AUC 需要两类都有
if len(np.unique(y_true)) > 1:
auc = roc_auc_score(y_true, y_prob)
else:
auc = np.nan
print(f"[{name}] ACC={acc:.4f} PRE={pre:.4f} REC={rec:.4f} F1={f1:.4f} AUC={auc:.4f}")
# ============ 7) 简单回测 ============
# 回归问题
def backtest_reg(test_df: pd.DataFrame, pred_col: str,
threshold: float, cost_bps: float, max_leverage: float = 1.0):
out = test_df.copy()
# 信号:预测值超过阈值才交易
raw_signal = np.where(out[pred_col] > threshold, 1.0,
np.where(out[pred_col] < -threshold, -1.0, 0.0))
position = np.clip(raw_signal, -max_leverage, max_leverage)
out["position"] = position
# 下一期真实收益(与标签对齐)
out["ret_fwd_1"] = out["close"].shift(-1) / out["close"] - 1
# 成本:按换手计算(单边bps)
# turnover = |pos_t - pos_{t-1}|
out["turnover"] = np.abs(out["position"] - out["position"].shift(1)).fillna(0.0)
cost_rate = cost_bps * 1e-4
out["cost"] = out["turnover"] * cost_rate
# 策略收益(假设t时刻持仓作用于t->t+1)
out["gross_pnl"] = out["position"] * out["ret_fwd_1"]
out["net_pnl"] = out["gross_pnl"] - out["cost"]
out = out.dropna(subset=["ret_fwd_1"]).copy()
out["equity"] = (1 + out["net_pnl"]).cumprod()
# 指标
ann_factor = 252 # 日频近似;若分钟级请自行改
mean_ret = out["net_pnl"].mean()
std_ret = out["net_pnl"].std(ddof=0)
sharpe = (mean_ret / (std_ret + 1e-12)) * np.sqrt(ann_factor)
cum_ret = out["equity"].iloc[-1] - 1
rolling_max = out["equity"].cummax()
mdd = ((out["equity"] / rolling_max) - 1).min()
print(f"[Backtest] CumRet={cum_ret:.2%} Sharpe={sharpe:.2f} MaxDD={mdd:.2%}")
return out
# 分类问题
def backtest_cls(test_df: pd.DataFrame, score_col: str):
out = test_df.copy()
out["prob_up"] = np.clip(out[score_col], 0.0, 1.0)
# 概率映射仓位:高置信度做多,低置信度做空,其余空仓
out["position"] = 0.0
out.loc[out["prob_up"] >= SIGNAL_PROB_THRESHOLD, "position"] = 1.0
out.loc[out["prob_up"] <= (1 - SIGNAL_PROB_THRESHOLD), "position"] = -1.0
# 下一期收益
out["ret_fwd_1"] = out["close"].shift(-1) / out["close"] - 1
# 换手与成本
out["turnover"] = np.abs(out["position"] - out["position"].shift(1)).fillna(0.0)
cost_rate = COST_BPS * 1e-4
out["cost"] = out["turnover"] * cost_rate
# 策略收益
out["gross_pnl"] = out["position"] * out["ret_fwd_1"]
out["net_pnl"] = out["gross_pnl"] - out["cost"]
out = out.dropna(subset=["ret_fwd_1"]).copy()
out["equity"] = (1 + out["net_pnl"]).cumprod()
ann_factor = 252
mu = out["net_pnl"].mean()
sd = out["net_pnl"].std(ddof=0)
sharpe = (mu / (sd + 1e-12)) * np.sqrt(ann_factor)
cum_ret = out["equity"].iloc[-1] - 1
mdd = (out["equity"] / out["equity"].cummax() - 1).min()
print(f"[Backtest] CumRet={cum_ret:.2%} Sharpe={sharpe:.2f} MaxDD={mdd:.2%}")
return out
# ============ 8) 分类任务和回归任务 ============
# 分类任务
def task_classification():
df = load_data(CSV_PATH)
feat_df = make_features(df)
feat_df["target"] = make_binary_label(feat_df, HORIZON)
feature_cols = [
"ret_1", "ret_5", "ret_10",
"vol_5", "vol_20",
"ma_gap_5", "ma_gap_20",
"vol_chg_1", "vol_ratio_5",
"hl_spread"
]
data = feat_df.dropna(subset=feature_cols + ["target"]).copy()
train, valid, test = time_split(data, TRAIN_RATIO, VALID_RATIO)
X_train, y_train = train[feature_cols].values, train["target"].values
X_valid, y_valid = valid[feature_cols].values, valid["target"].values
X_test, y_test = test[feature_cols].values, test["target"].values
# 用回归器拟合 0/1 标签
model = RandomForestRegressor(**RF_PARAMS)
model.fit(X_train, y_train)
s_train = model.predict(X_train)
s_valid = model.predict(X_valid)
s_test = model.predict(X_test)
evaluate_cls(y_train, s_train, "train", thr=CLS_THRESHOLD)
evaluate_cls(y_valid, s_valid, "valid", thr=CLS_THRESHOLD)
evaluate_cls(y_test, s_test, "test", thr=CLS_THRESHOLD)
fi = pd.Series(model.feature_importances_, index=feature_cols).sort_values(ascending=False)
print("\nTop feature importances:")
print(fi)
bt = test[["datetime", "close"]].copy()
bt["score"] = s_test
bt_res = backtest_cls(bt, "score")
bt_res.to_csv("backtest_result.csv", index=False)
print("\n已保存: backtest_result.csv")
# 回归任务
def task_regression():
# 1) 读数
df = load_data(CSV_PATH)
# 2) 特征+标签
feat_df = make_features(df)
feat_df["target"] = make_label(feat_df, HORIZON)
feature_cols = [
"ret_1", "ret_5", "ret_10",
"vol_5", "vol_20",
"ma_gap_5", "ma_gap_20",
"vol_chg_1", "vol_ratio_5",
"hl_spread"
]
# 去除NaN(滚动窗口和shift导致)
data = feat_df.dropna(subset=feature_cols + ["target"]).copy()
# 3) 时间切分
train, valid, test = time_split(data, TRAIN_RATIO, VALID_RATIO)
X_train, y_train = train[feature_cols], train["target"]
X_valid, y_valid = valid[feature_cols], valid["target"]
X_test, y_test = test[feature_cols], test["target"]
# 4) 训练
model = RandomForestRegressor(**RF_PARAMS)
model.fit(X_train, y_train)
# 5) 预测评估
pred_train = model.predict(X_train)
pred_valid = model.predict(X_valid)
pred_test = model.predict(X_test)
eval_regression(y_train, pred_train, "train")
eval_regression(y_valid, pred_valid, "valid")
eval_regression(y_test, pred_test, "test")
# 特征重要性
fi = pd.Series(model.feature_importances_, index=feature_cols).sort_values(ascending=False)
print("\nTop feature importances:")
print(fi.head(10))
# 6) 回测
bt = test[["datetime", "close"]].copy()
bt["pred"] = pred_test
bt_res = backtest_reg(
bt,
pred_col="pred",
threshold=SIGNAL_THRESHOLD,
cost_bps=COST_BPS,
max_leverage=MAX_LEVERAGE
)
# 导出结果
bt_res.to_csv("backtest_result.csv", index=False)
print("\n回测结果已保存到 backtest_result.csv")
def main():
# 分类任务流程
task_classification()
# 回归任务流程
task_regression()
if __name__ == "__main__":
main()