最近我一直在想一个问题:我们平时看了那么多研报、纪要、行业分析,最后真正能沉淀成交易动作的,到底有多少?
很多时候,一篇材料看完,当下是有感觉的。
比如:这个行业可能在周期底部;某家公司成本优势很强;某个商品供需关系快要反转;某个资产未来 12 个月赔率不错。逻辑都能讲通,图也挺漂亮,目标价也挺诱人。
但问题来了:然后呢?
如果我真的认可这个投研结论,接下来应该买什么?怎么买?买多少?什么时候加?什么时候认错?哪些数据变化说明原来的判断已经不成立?
这些问题不回答,投研结论就很容易停在“我觉得有机会”这一层。看起来很兴奋,真到下单时又很模糊。
这也是我做并使用 r2t-pipeline (Report to Trading Plan) 这个 skill 的原因。它不是一个简单的研报摘要工具,而是想把投研结论往前推一步:推到一份可以执行、可以复盘、也可以被别人质疑的交易计划里。
先说它解决的痛点
我自己的感受是,投研和交易之间有一个断层。
投研材料里通常会告诉你:
- 行业现在处在什么位置;
- 核心变量是什么;
- 推荐什么标的;
- 目标价大概在哪里;
- 有哪些风险。
但交易真正需要的是另一套问题:
- 这个结论用股票表达,还是用期货、转债、ETF 表达?
- 现在是左侧试探,还是右侧确认?
- 仓位应该怎么分批?
- 最大回撤我能不能接受?
- 如果判断错了,哪个指标会先提醒我?
- 如果判断对了,止盈和退出节奏是什么?
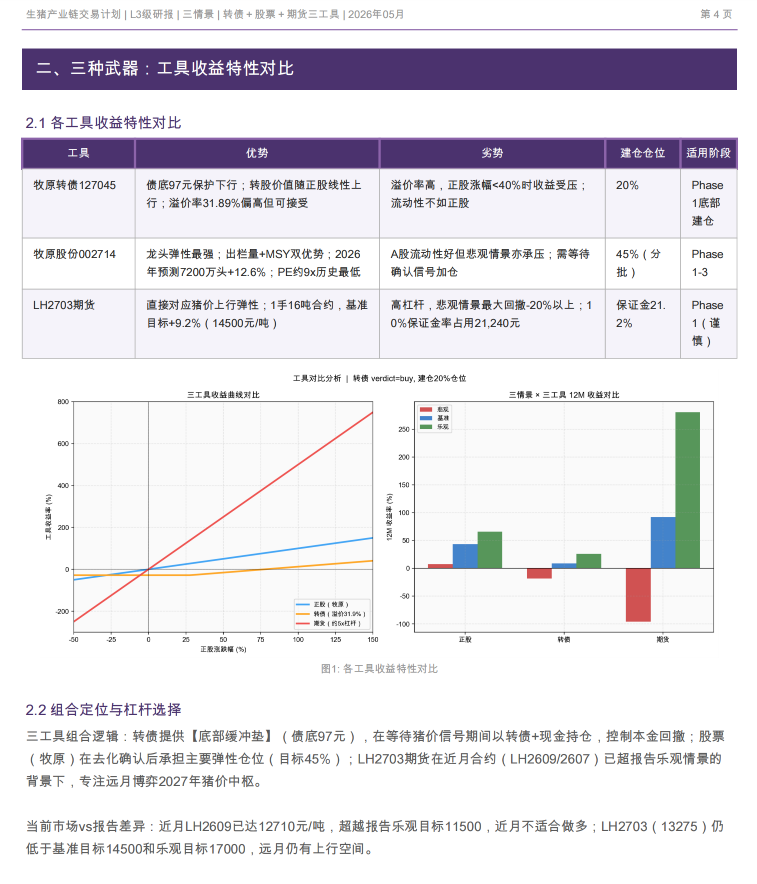
上图由该skill生成
以前这些问题大多靠自己临场补。临场补就有一个问题:行情一波动,情绪很容易接管判断。
r2t-pipeline 想做的事情,就是把这些问题提前写进流程里。它不替你判断一定涨或一定跌,但会逼你把“为什么买、怎么买、错了怎么办”提前说清楚。
它大概是怎么跑的
这个 skill 的输入不是一句 prompt,而是一套材料和约束:投研材料、资金规模、目标收益、可接受回撤、计划名称等。
跑起来之后,它会按阶段推进,最后输出一份固定 9 章结构的交易计划。
flowchart TD
A[投研材料与交易约束] --> B[提取核心结论]
B --> C[判断材料完整度 L0-L3]
C --> D[选择交易工具]
D --> E[Panda Data 更新行情]
E --> F[构建情景框架]
F --> G[设计仓位与买卖点]
G --> H[盈亏测算与 Monte Carlo]
H --> I[生成图表]
I --> J[输出交易计划 PDF]

上图由该skill生成
这里面我最喜欢的是两点。
第一,它会先判断材料的信息完整度。
有些投研材料很完整,会给多情景、目标价、概率、时间节点;有些材料只是一个方向判断;还有些只是定性分析。r2t-pipeline 不会把所有材料都硬加工成同样精细的模型,而是分成 L0 到 L3,不同等级走不同粒度的交易计划。
这点很关键。因为投研里最危险的不是不知道,而是“材料没写,但我脑子里自动补齐了”。比如材料只说“周期底部”,但你自己脑补了价格、概率、时间和收益路径。最后计划看起来很完整,其实很多数字都没有来源。
第二,它会接入 Panda Data 来校正和更新。
Panda Data 是 PandaAI 量化平台的数据接口,我在这个 skill 里用它拉取股票、期货等历史行情数据。也就是说,交易计划不是只停留在研报里的静态判断,而是会用真实市场数据再过一遍。
比如研报里给了一个目标价区间,但当前价格已经变了;研报里看的是某个期货合约,但主力合约结构已经切换;或者某个标的过去 18 个月的波动率、支撑位、压力位和回撤特征,跟文字里的感觉并不完全一致。这个时候,Panda Data 拉下来的行情数据就会成为一次现实校准。
这也是我觉得 AI 投研工具必须补上的一块:不能只有“读材料”,还要有“接数据”。没有数据更新,AI 很容易变成一个讲得很顺的文本整理器;接上 Panda Data 之后,它才更像一个能落到交易桌上的工作流。
它不是摘要器,而是计划生成器
如果只是摘要器,它最多帮我回答:这篇材料讲了什么、推荐了什么、风险是什么。
但交易计划要回答更多。
第一层,是投研结论本身。
比如周期位置、核心矛盾、催化剂、目标价、风险因素。这些是研究的基础。
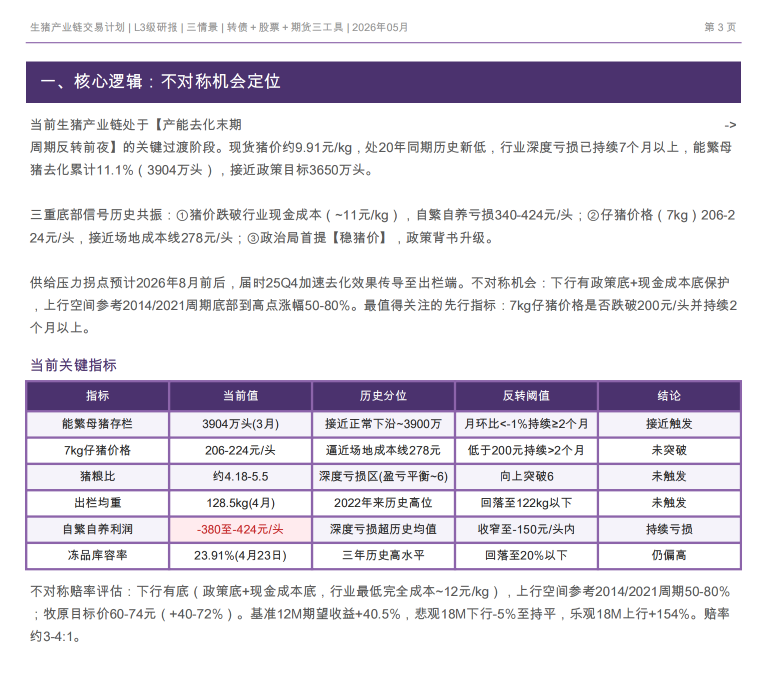
上图由该skill生成
第二层,是交易工具。
同一个投研结论,可以用不同工具表达。股票表达的是公司价值重估,期货表达的是商品价格波动,转债可能是在防守和弹性之间找平衡。工具选错了,方向看对也可能赚不到该赚的钱。
第三层,是行情校正。
这就是 Panda Data 的价值。它把最新或近一段时间的行情数据拉进来,让计划不只基于研报里的静态数字,还能结合真实价格、波动率、支撑压力、成交变化去调整。对交易来说,这一步很重要,因为市场不会等研报更新。
第四层,是仓位和执行。
什么时候建仓,什么时候加仓,什么时候止损,哪些信号触发复盘,都要提前写清楚。否则再好的投研结论,也可能在执行时变形。
所以我对这个 skill 的定位是:它不是帮我“总结观点”,而是帮我把观点变成一套可检查的行动方案。
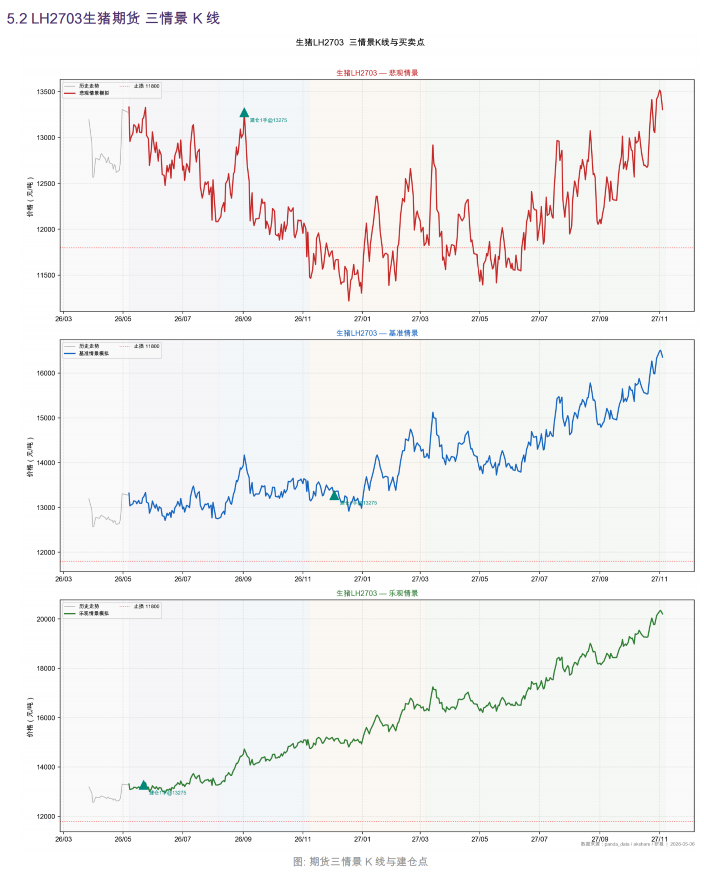
上图由该skill生成
用下来我觉得好的地方
第一个好处,是它会强迫我结构化思考。
投资研究很容易被一个顺畅的故事带着走。逻辑越顺,人越容易忽略反面证据。这个 skill 会把周期位置、目标价格、情景概率、关键指标、风险触发条件都拆出来。只要有一项说不清楚,就说明这个计划还不够扎实。
第二个好处,是它把“研究”和“交易表达”接上了。
看对行业,不等于买对标的;买对标的,不等于买对价格;买对价格,也不等于仓位合适。r2t-pipeline 会把标的、工具、买卖点、盈亏结构放在同一个计划里看,这比单独看一篇研报更接近真实交易。
第三个好处,是 Panda Data 让计划更贴近市场。
这一点我想多说两句。很多 AI 投研应用的问题是,生成内容很顺,但数据更新不够及时,或者没有跟行情真正打通。Panda Data 提供的就是这个底座:股票、期货、指数等数据可以通过接口接入,策略分析和图表生成就有了可更新的数据来源。
这对交易计划特别重要。因为交易计划不是写完就完了,它本质上是一个动态假设。行情变化之后,支撑位、压力位、波动率、回撤空间都会变。如果没有数据接口,计划很容易停留在“写得很好看”;接入 Panda Data 后,至少可以往“持续校正”走一步。
第四个好处,是复盘更方便。
如果交易计划只是脑子里的想法,失败后很难说清楚是研究错了,还是执行错了,还是风控一开始就没设计好。结构化文件、行情数据、图表、情景表和最终 PDF,会把当时的假设留下来。之后复盘时,不用靠记忆。
第五个好处,是风控会被提前摆上桌。
普通研究往往最后才写风险提示,交易计划不行。最大回撤、止损条件、跟踪指标、失效信号,都必须在动手之前写清楚。这样交易就不是单纯押一个观点,而是在管理一个带边界的假设。
当然,它也不是万能的
第一个限制,还是输入质量。
如果投研材料本身只有一句“看好”,没有价格、时间、指标、验证路径,那 skill 能做的是降级处理,而不是凭空造出确定性。它可以让计划更规范,但不能把薄材料自动变成深度研究。
第二个限制,是它不能替你负责。
交易计划不是投资建议。它只是把判断、数据、假设和动作组织起来,让风险暴露更清楚。真正下单之前,仍然要结合账户规模、流动性、风险偏好和市场状态做决定。
我自己的一个体会
以前我看投研材料,最容易关注的是结论:看多什么、目标价多少、空间多大。
现在我会更习惯追问:
- 这个结论能不能被验证?
- 用什么数据验证?
- 当前市场价格是否已经反映了一部分预期?
- 如果我现在动手,风险收益比还成立吗?
- 如果错了,我在哪一步退出?
这几个问题一问,Panda Data 的作用就很自然了。
因为很多问题不能只靠文字回答。比如“现在是否已经 price in 了”,需要看行情;“波动率是否能承受”,需要看历史价格;“支撑位是否有效”,需要看 K 线;“期货和股票是否背离”,也需要数据。
所以我现在对 AI 投研工具的期待,不是让它给我一个更绝对的答案,而是让它把结论拆开,把数据接上,把行动路径写清楚。
r2t-pipeline 做的就是这件事。
后面我还想继续优化什么
第一,把每天的市场环境接进来,做更精细的交易操作。
用来解决的是交易计划落地后的日度执行问题:每天市场环境都在变,原来的计划需要根据新的信息做细微调整。这个新 skill 会结合当天的市场情绪、板块分化、资金流向、拥挤程度,以及利率、美元指数、油价、铜价、金价等宏观和跨资产指标,帮助判断当天应该怎么操作。
它不是推翻原来的交易计划,而是在计划框架内做日度校准。比如,今天适不适合加仓?应该主动进攻,还是先收缩仓位?当前盈亏比有没有变差?胜率是否因为市场环境变化而下降?仓位要不要从 40% 调到 25%?我的目标是,在不改变大方向判断的前提下,通过更精细的日度操作,尽量增厚收益、降低亏损。
第二,参数调整要更交互。
本金、最大回撤、目标收益、仓位上限、情景概率,这些变量对最终计划影响很大。如果能有一个更顺手的参数面板,就可以快速比较不同风险偏好下的方案。
第三,资产类别可以继续扩展。
目前这个流程已经覆盖股票、期货、转债等常见工具,但不同市场有不同规则。比如 ETF、期权、海外股票、利率品种,都可以继续做更细的适配。
第四,输出可以更多样。
完整的 9 章 PDF 适合归档和分享,但实际使用时,有时候还需要更短的版本,比如一页纸决策卡、执行清单、每日跟踪表、复盘模板。这些都是很自然的下一步。
最后
r2t-pipeline 对我最大的改变,是让我不再满足于“这篇材料讲得挺有道理”。
我会继续往下问:这个投研结论能不能变成一个有边界的交易计划?有没有数据校正?有没有执行路径?有没有认错机制?
AI 在这里最有价值的地方,不是替我拍脑袋判断涨跌,而是把投研结论、Panda Data 行情数据、情景假设、仓位设计和风控规则放进同一个流程里。
这样做不能保证赚钱,但至少能让每一次行动更清楚:我为什么做,基于什么数据做,准备承担什么风险,以及什么时候承认自己错了。
对我来说,这比单纯多读几篇研报,价值要大得多。
最后预告:该Skill已经贡献给PandaAI,将发布在其即将上线的新产品中,敬请期待。