今天我们来探讨一个十分重要且应用广泛的统计学概念——置信区间。
置信区间(confidence interval)是推断统计中参数估计的核心分支,是对 “点估计” 的补充与完善。以下是从定义、原理、分类到计算公式的完整总结,适配量化投资实战理解。
你或许在用户调研报告中见过这样的表述:“用户满意度平均得分为80,95%置信区间为[76.08, 83.92]”——这意味着我们有95%的把握认为,真实的用户满意度均值落在76.08至83.92分之间。类似地,美国大选中公布的投票率(如“52% ± 3%”),其本质也是通过置信区间来反映统计结果的可靠性。
那么置信区间究竟代表什么?它是如何计算的?又该如何解读?
一、核心逻辑:为什么需要置信区间?
统计学两大核心分支——描述性统计与推断统计,共同构成数据分析的基础框架。其中推断统计的核心功能,是通过样本统计量(如样本均值)对总体参数(如总体均值)进行科学估计,具体分为点估计和区间估计两种方法。
1. 点估计的局限性
点估计比较简单、好理解,但没有说明可能的误差有多大。
- 点估计(Point Estimation):用样本统计量直接代替总体参数。
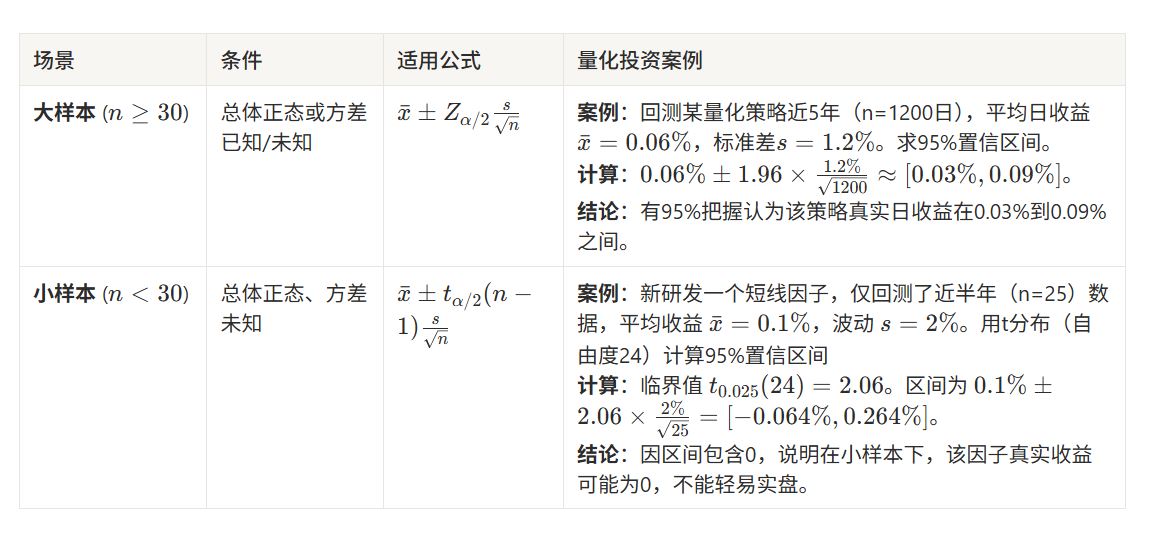
量化案例:用过去1年(250个交易日)回测的策略平均日收益0.05%,直接估计该策略未来长期日收益为0.05%。 - 缺陷:无法判断这个0.05%“准不准”。如果样本波动大,单次点估计误差可能很大。
2. 置信区间的核心价值
置信区间在点估计基础上,给出了误差范围和可信度。
- 案例:该策略未来长期日收益的95%置信区间为[0.02%, 0.08%]。
- 解读:我们有95%的把握,认为该策略的真实长期日收益落在0.02%到0.08%这个区间内。
我们都知道,在开展实验或撰写评估报告时,仅依靠平均值(样本统计量)是远远不够的。平均值只能体现数据的中心位置,却无法反映结果的可靠性。这时置信区间就发挥了作用,它在均值的基础上给出了一个可信范围。
置信区间是常用的统计推断方法,可用于估算不同类型的参数。今天我们将介绍最常用的、总体标准差σ已知情况下的均值置信区间。
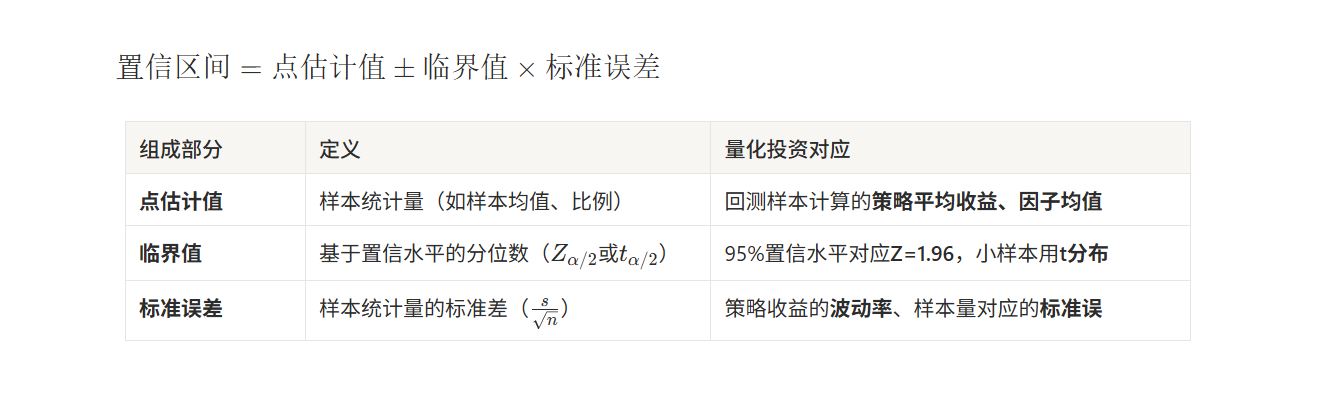
除此之外,还有比例置信区间、差值置信区间等。不同参数的置信区间计算公式略有差异,但结构一致,均为点估计值±临界值×标准误差。
二、置信区间的基础原理
1. 核心公式结构
所有置信区间计算均遵循通用公式:
2. 置信水平的含义
- 定义:预先设定的概率(常用95%、90%),记为。
- 解读:不是“参数在区间内的概率”,而是“构造的区间包含真值的概率”。
95%置信水平表示:如果重复进行100次不同时期的回测,构造100个置信区间,大约有95个区间会包含该策略的真实收益。
我们先从公式入手理解,置信区间常用英文(confidence interval)缩写CI表示。不必被公式吓到,其结构十分简单,即均值加减标准误差。公式中的 代表样本均值,加减意味着需要在均值的基础上增减一段数值,以此得到区间的上下限。σ为标准差,反映数据的离散程度;n为样本量。
其中最为关键的是 值,也被称为Z分数或标准分数,它的作用是:在标准正态分布曲线上,从中心点出发,向左右两侧延伸多少个标准差,才能覆盖我们所需的置信水平。
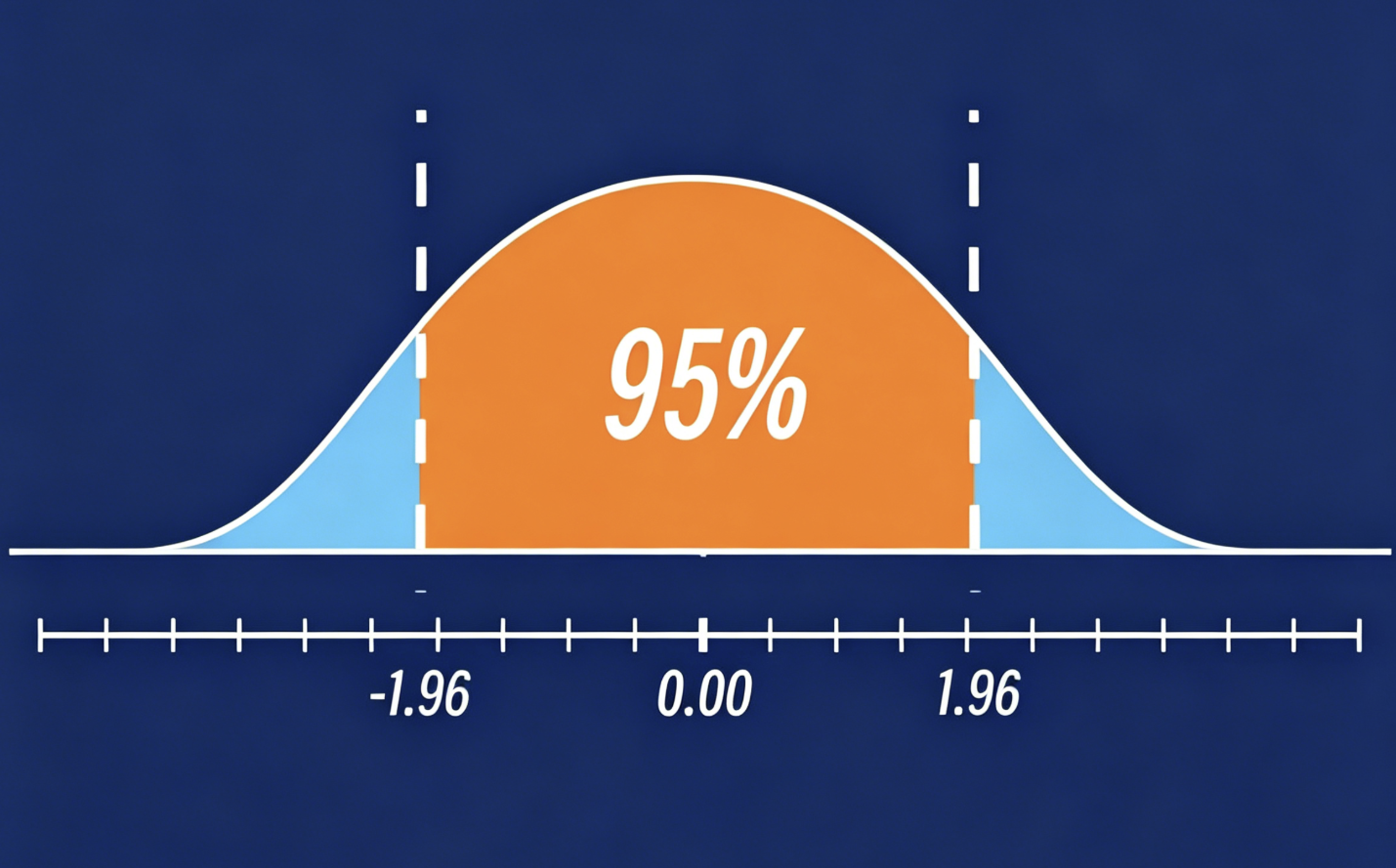
首先来看大家熟悉的钟形曲线,这就是标准正态分布,曲线下面积为1,即100%,代表正态分布变量所有可能取值的概率总和。
我们回顾一下,置信水平指的是我们希望该区间包含真实值的把握程度。常用的置信水平有90%、95%和99%。以99%置信水平为例,意味着我们希望以该把握程度捕获总体真实值。构建95%置信区间时,选取中间95%的区域作为可信范围,剩余5%为估算错误的风险,这部分被称为α,即显著性水平。
由于标准正态分布具有对称性,5%会被平分至两侧,每侧各占2.5%,也就是图中红色的尾部区域。由此可知公式中的 即为 ,我们只需查询其对应数值并代入公式即可。
通过Excel函数、专业统计软件计算或手动查表,都能得出 。若采用查表法,需要注意标准正态分布表依据累积概率查询,即用我们需要的0.95区域加上左侧红色区域的0.025,通过0.975查找对应的Z值。
1.96究竟代表什么?它的含义是:在标准正态分布中,从中心均值出发,向左右各移动1.96个标准差,就能覆盖中央95%的概率区域,由此构建出95%置信区间。
至此我们了解了置信水平与Z分数的对应关系:置信水平越高,Z值越大,置信区间也就越宽。建议大家直接牢记这些常用置信水平对应的Z值。
三、核心场景与公式
根据数据类型和样本量,分为以下核心场景:
1. 单个总体均值的置信区间(最常用)
适用于策略收益、因子收益等连续型数据。
2. 单个总体比例的置信区间
适用于策略胜率、信号命中率等比例数据。

3. 两个总体参数之差的置信区间
适用于对比两个策略、两个因子的效果差异。
(1) 两个策略收益之差 ()

(2) 两个策略胜率之差 ()
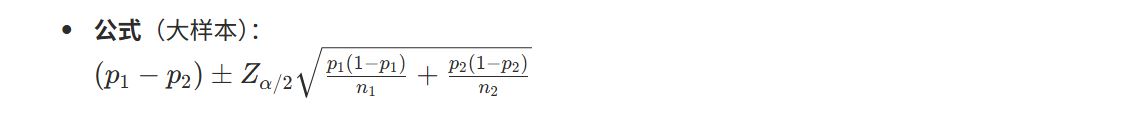
四、关键结论与特性
1. 影响置信区间的因素
- 置信水平:水平越高(99%>95%),临界值越大,区间越宽,可信度越高但精度越低。
- 样本量:越大,标准误越小,区间越窄,估计越精确。
- 波动率:数据波动越大(s大),标准误越大,区间越宽,不确定性越高。
2. 正态分布与3σ原则(量化基础)
- 1σ (68.27%):策略收益约有68.27%的概率落在范围内。
- 2σ (95.45%):约95.45%的概率落在。这是量化中常用的95%置信水平近似值。
- 3σ (99.73%):约99.73%的概率落在。用于识别极端风险(黑天鹅事件)。
理解原理后,我们通过量化案例来实战。假设需评估某股票平均日收益率,现抽取 100 个交易日作为样本。基于 95% 置信水平对应的 Z 值 1.96 及样本数据,代入公式计算后,我们得到该区间的上下限。因此,该股票平均日收益率的 95% 置信区间为 [0.05, 0.072]。
最后我们要正确解读这一区间。很多人会脱口而出:“该股票的总体真实平均收益率有95%的概率落在这个区间内。”这是典型的错误表述。
我们需要牢记:总体均值是固定数值,恒定不变,不存在不确定性,也就没有概率可言。我们不能说真实值以某一概率落入计算出的区间。
打个比方,飞镖靶心是总体真实满意度均值,每次投中位置代表一次抽样得到的样本平均满意度,以落点为圆心画出的圈就是置信区间。你可以说,我有95%的把握这个圆圈能包含靶心;或者长期重复投掷,95%的圆圈都会包围靶心。但你不会说靶心在移动,有95%的概率落入我的圆圈内。
不确定性来源于抽样过程与由此计算出的置信区间。我们可以描述区间包含真实值的概率,或是对该区间包含真实值的置信程度,却不能用来描述真实值落入某一区间的概率。
若采用相同方法重复抽样,并依据样本构建置信区间,约95%的区间会包含总体真实均值。以下为几种正确解读方式可供参考。
所以置信区间的真正含义是:大量重复抽样并每次计算置信区间后,约95%的区间会包含总体真实均值。理解了这一核心内涵,判断各类表述的正误就会变得十分简单。
五、量化投资实战应用总结
- 策略有效性验证:计算策略收益的置信区间,若区间下限 > 0,则有较高把握认为该策略长期可盈利。
- 因子筛选:估计因子收益的置信区间,剔除区间包含0的无效因子。
- 风险控制:通过置信区间量化策略收益的波动范围,用于仓位管理和止损设置。
- 策略对比:对比两个策略收益差的置信区间,判断差异是否具有统计学意义。
以上就是置信区间的核心知识点。