很多刚接触量化和使用panda ai的小伙伴,一跑完回测就会看到一大堆指标: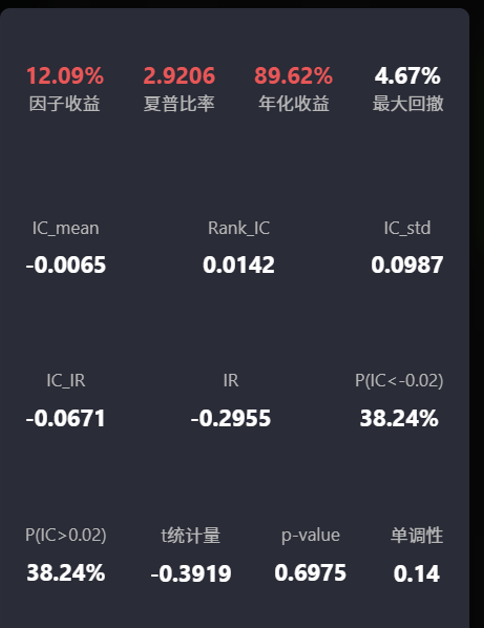
包括我一开始我也不知道这些指标是什么?看着很专业,其实一脸懵:这些是干嘛的?之间有什么关系?我到底该看哪个来调整我的因子和策略?我会尝试在这篇文章用最白话的方式,把这些一次讲清楚。
一、先分清两个层次:因子 vs 策略
所有这些指标,大致分成两类:
1. 因子评价指标:看“选股/选合约信号”本身好不好
这类指标评价的是:你的“打分规则”(因子)到底能不能预测未来收益?
典型代表:
**IC_mean
Rank_IC
IC_std
IC_IR
P(IC>0.02)、P(IC<-0.02)
t统计量、p-value
单调性、正向因子/负向因子、几组分组
**
2. 策略/组合评价指标:看“资金曲线”好不好
这类指标评价的是:用这些因子真的去下单之后,你的资金曲线漂不漂亮?
典型代表:
**年化收益
最大回撤
夏普比率(Sharpe)
IR(Information Ratio)**
类比一下:
因子 = “给考生打分的预测模型”:能不能预测谁考高分,策略 = “真拿钱去赌这些学生”:最后亏还是赚
结论:
因子好(IC好)≠ 策略一定赚钱, 策略好 ≠ 里面的因子都科学,有可能纯靠运气。所以做量化先把因子搞清楚,再把因子组合成一个好的策略。后面先讲因子侧的指标,再讲策略侧的指标,最后说怎么用它们调优。
二、因子评价指标:IC、Rank IC、IC_IR 等
1. IC 是什么?
IC 全称 Information Coefficient(信息系数),本质是:某一天横截面上,“因子分数”和“未来收益”之间的相关系数。更具体一点:某天 t,你对一篮子股票/期货计算因子 f_i(t) 未来一个窗口(比如 t+1 天)的收益 r_i(t+1) 在这一天横截面内,算相关系数 corr(f(t), r(t+1))
理解:
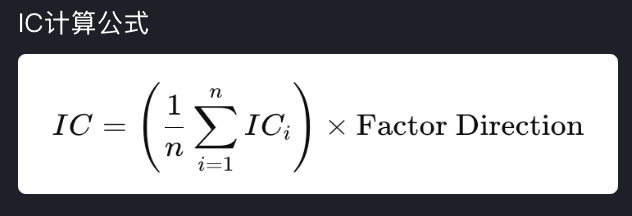
因子高的标的,未来更容易涨 → 当天 IC 为正
因子高的反而容易跌 → IC 为负
|IC| 越大,说明“因子排序”和“未来收益排序”越一致
现实世界里:
IC 在 0.02~0.05 已经很有用。IC 不会像教科书例子那样到 0.8,那是“几乎完美线性”的关系,金融里很少
2. Rank_IC:为啥要“秩相关”?
正常 IC:用原始因子值和原始收益算 Pearson 相关
Rank_IC:先把因子、收益都转成“名次”(排序),计算 Spearman 秩相关
为什么要 Rank?
因子通常只在“排序”有意义,绝对数值不重要
对极端值不敏感,更稳健
实战中:
Rank_IC 比 IC 更常用,你看到的 Rank_IC_mean 就是 Rank_IC 的时间平均。
3. IC_mean / Rank_IC_mean:因子的平均“方向对不对”
IC_mean = 多期 IC 的时间平均值
Rank_IC_mean 同理
经验值:
0.02~0.03:已经可以考虑
0.05~0.1:非常强
≈0:说明这个因子基本没啥预测能力
明显为负:有可能是“反向因子”,反着用也许有价值
4. IC_std:因子表现稳不稳定
IC_std = IC 的标准差,表示 IC 在时间上的波动大小。
IC_mean 大,但 IC_std 也巨大 → 因子有时候超神,有时候超坑
IC_mean 中等,但 IC_std 很小 → 因子比较“平稳耐用”
这就引出下一个:
5. IC_IR:信息比率(针对 IC 的)公式:IC_IR = IC_mean / IC_std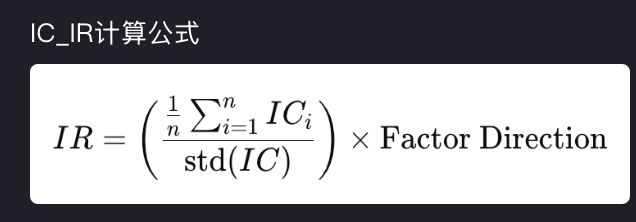
含义:
分子:平均预测能力大小
分母:预测能力的波动大小
IC_IR 越大越好:
0.5 以上已经不错
~1 属于相当优秀
很多成熟因子 IC_mean 可能只有 0.02~0.03,但因为 IC_std 不大,IC_IR 仍然比较可观。
6. P(IC>0.02)、P(IC<-0.02):因子“多数时间”方向如何?
## 这两个是简单的统计频率:
P(IC>0.02):在所有样本期中,有多少比例的 IC 明显偏正
P(IC<-0.02):有多少比例 IC 明显偏负
直觉:
P(IC>0.02) 高、P(IC<-0.02) 低 → 因子大部分时间方向正确
两边都不低 → 因子很“情绪化”:时灵时不灵
应用:
如果因子平均 IC 不错,但 P(IC<-0.02) 也不小,可以考虑:
只在某些市值/行业/波动率区间启用该因子
出现“因子失效”迹象时减仓或暂停该因子
7. t统计量 和 p-value:这个因子是不是纯玄学?
我们在时间维度上做一个假设检验:
零假设 H0:因子无效,IC_mean = 0
备择 H1:因子有效,IC_mean ≠ 0
t 值大致是:
t = IC_mean / (IC_std / sqrt(T)) (T = 样本期数)
|t| 越大:越不可能是偶然。p-value:在“因子其实没用”的前提下,出现这么极端 t 的概率
经验:|t| > 2,大致对应 p < 0.05 → 可认为“统计上显著”
注意:t 明显,说明“历史上看不是纯随机”。但不保证未来一定继续有效,只能说有统计依据。
8. 单调性 + 正向因子/负向因子 + 分组数(几组?)
8.1 分组回测是什么?
经典做法是“分层回测”:
每个调仓日按因子从大到小排序
分成 N 组(N=5 或 N=10 最常见)
分别持有每一组,看归因结果
如果因子是正向的:
因子值越大,未来收益应该越高
预期:Q5 > Q4 > Q3 > Q2 > Q1(Q5 为最高因子组)
如果因子是负向的:
因子越低,未来收益越高
预期:Q1 > Q2 > Q3 > Q4 > Q5
单调性好 = 分组收益基本按这个顺序排列。
8.2 正向因子 vs 负向因子
看 Rank_IC_mean 的符号:
0:正向因子,因子高 → 收益高
< 0:负向因子,因子高 → 收益低
再用分组收益验证:
正向因子:高因子组收益明显更好
负向因子:低因子组收益明显更好
实战上:
正向因子:多高因子组合,空低因子组合
负向因子:反着用(多低因子组合,空高因子组合),或者直接取反 -factor 当作新因子
8.3 分几组?5 组 vs 10 组是什么意思?
5 组(五分位):每组样本更多,结果更稳 分辨率稍粗
10 组(十分位):看得更细致 但每组标的变少,会更多噪音
实践建议:
先看 5 组整体是否单调。再看 10 组是否只有极端组(最高/最低)明显有收益,其它组平平。如果只有极端两组有显著超额收益,那说明:因子“中间区域”没啥用,策略可以只做“多高、空低”的 Long-Short。
三、策略/组合评价指标:年化、回撤、Sharpe、IR
因子只是打分,最终还要看“真拿钱买了之后,资金曲线长什么样”。这就是策略层的指标。
1. 年化收益(Annualized Return)
定义:
把回测期间的总收益,折算到“每年平均涨多少”的速度。
例:3 年从 100 万涨到 133.1 万:
总收益 = 33.1%
年化 ≈ (1.331)^(1/3) - 1 ≈ 10%/年
年化收益只看“平均赚多少”,不看“怎么一路颠簸过来的”。
2. 最大回撤(Max Drawdown)
回撤就是:某一历史高点跌到后面最低点的跌幅。
最大回撤就是:
整段回测中,最惨的那一坑。
意义:
心理上:你能不能扛得住从 100 万跌到 70 万再涨回来?
风控上:机构/FOF 很看重最大回撤
高收益 + 高回撤 = 高杠杆赌徒风格。
3. 夏普比率(Sharpe Ratio)
简化公式:
Sharpe = 平均收益 / 收益标准差
(严格来说是“超额收益 / 波动率”,但很多回测无风险利率直接当 0)
含义:
单位风险带来了多少收益?
经验:
年化 Sharpe > 1:可以说不错
1.5:很优秀
2:非常强(当然要警惕过拟合)
4. IR(Information Ratio,组合的)
注意和上面讲的 IC_IR 区分:这里的 IR 是 组合的“超额收益质量”。
定义:
IR = (组合收益 – 基准收益) 的均值 / 标准差
基准可以是沪深300、某指数等
区别:
Sharpe:评估绝对收益/风险
IR:评估相对基准的超额收益/超额波动
对于做主动管理、量化选股的策略,IR 常常比 Sharpe 更有意义。
四、这些指标怎么一起用?从因子到高夏普策略的路径
第一步:因子阶段——先看“信号是否靠谱”
对每个因子,建议最少看这些:
Rank_IC_mean / IC_mean
大小、符号
IC_std、IC_IR
稳定性如何
P(IC>0.02)、P(IC<-0.02)
大部分时间方向是不是对的
t统计量、p-value
历史上是否“统计显著”,不是玄学
分组回测的单调性
正向因子:高因子组收益更高
负向因子:低因子组收益更高
如果一个因子:
Rank_IC_mean ~ 0.03、IC_IR ~ 0.6、t 显著分组呈明显单调那么它基本就是一个“有用因子”,可以纳入策略。
第二步:策略阶段——把好因子变成好资金曲线。这一步才是你回测里看到“年化、回撤、Sharpe、IR”的地方。
关键设计点:用哪些分组?例如只多 top20%,空 bottom20%(极端分组)权重怎么算?等权、市值权重、按因子强度加权
换手和频率
调仓越频繁,年化收益↗、波动和成本也↗,Sharpe 不一定变好
风险控制 行业中性、风格中性 单票权重上限、仓位上限
观察策略的:年化收益:值不值
最大回撤:能不能睡着觉
Sharpe:单位风险收益
IR:对基准的超额收益质量
第三步:联动优化
常见的几种情况和思路:因子 IC 很好,但策略 Sharpe 一般:检查是否杠杆太高、仓位太满、没有控制行业/风格风险。降杠杆、优化权重,Sharpe 通常会提高。Sharpe 很高,但年化收益不高:可以考虑适度加杠杆,在可接受回撤范围内放大利润。某段时间回撤异常大:回头看那段时间的 IC 表现,是否因子集体失效
找出“因子容易翻车的环境”,以后避开或降权
五、正向因子 & 负向因子,到底怎么判断和使用?
判断方法:
看 Rank_IC_mean 的符号:
0:正向因子
<0:负向因子
看分组单调性是否符合预期:
正向因子:高因子组收益明显更高
负向因子:低因子组收益明显更高
在策略里怎么用?
正向因子:
因子越高,买得越多;因子越低,卖/空得越多
负向因子:
因子越低,买得越多;因子越高,卖/空得越多或者直接用 -factor 替换原因子,当成一个新的正向因子,多因子时还可以:把多个正向因子线性组合(加权)负向因子取反后一起加权。
六、对新手的一个“实战路线流程”
如果你刚入门,可以按这个流程来:
先做单因子实验:
计算每日 Rank_IC、画出 IC 的时间序列
统计 IC_mean、IC_std、IC_IR、t、p-value
做 5 组/10 组分层,看分组收益是否单调
筛掉玄学因子:
IC_mean ≈0、IC_IR 很小、t 不显著 → 放弃
单调性乱七八糟 → 谨慎使用
用剩下的好因子做组合:
按分组构建多空组合(多高空低)控制行业/市值暴露
观察策略指标:
年化、最大回撤、Sharpe、IR 不盯着年化单指标,要看“收益/风险”的整体质量
迭代:
因子层面继续寻找新因子、改造旧因子。策略层面微调权重、频率和风险控制
一步步下来,你就会发现:回测报告里那堆看不懂的指标,其实是一个完整的“诊断工具箱”,
前半套用来判断“因子信号靠不靠谱”,后半套用来判断“策略资金曲线稳不稳定”。你只要按这个逻辑去看,就不会再被一堆 IC、IR、Sharpe 吓到,而是知道:先看哪几个因子指标筛因子,再看哪几个策略指标调组合。
七、怎么判断自己的因子是不是过拟合?
前面讲的 IC、单调性、t 值,都是在**“样本内”**看起来很漂亮的指标。但量化里最大的坑就是:
在历史数据上调得完美,未来一跑就崩——这就是过拟合。
简单说:
你不是发现了“市场规律”,而是“记住了历史答案”。
模型复杂度越高、调参越狠、尝试因子越多,越容易过拟合。
下面给几个对新手比较落地的判断方法。
1. 时间切割:训练集 / 验证集 / 测试集
最基础也是最重要的一条:
把历史按时间切段:
比如:
2014–2018:开发/调参(训练集)
2019–2020:验证(验证集,用来选方案)
2021–2024:完全不用来调参,只用来检验(测试集)
你的因子如果:
在训练集:IC、IC_IR、单调性都很好
在验证集:还能保持大致水准(略微下降很正常)
在测试集:表现没有“断崖式掉到 0 或变成负”
那大概率 不过拟合。
相反:
训练集超级好(IC_mean=0.08、IC_IR=1.5)
验证集/测试集基本归零甚至变负
这种十有八九是过拟合——你只是把训练区间的噪音模式“背下来了”。
给新手一句话:因子不要只在一段历史上调,要跨时间段验证,“前后两段历史”都行才有说服力。
2. 横截面切割:换一批标的再测
除了时间,还可以换一批不同的标的来验证:
例子(股票):
在沪深 300 成分股上开发因子
再拿到中证 500、1000 上看 IC 和单调性
例子(期货):
在黑色系(螺纹、铁矿)上开发
再拿到有色、农产品、股指期货上验证
如果你的因子:
只在一小撮标的(比如某个行业、某个品种)表现极好
换别的标的一跑就废
那很可能是“记住了某一个局部品种的历史特征”,而不是普适规律。
当然,有些因子本来就是行业/品种特定的(比如只针对成长股),这个要自己知道边界,不能拿去吹“全市场有效”。
3. 滚动/走进式回测:模拟你真的“只知道过去”
做因子时一个经典错误:
用全样本历史算一个“全局最优参数”,然后再拿同一段历史回测。这就像:开考前偷看了整套试卷,再回来选出一套“完美复习计划”,然后拿同一套试卷考试。更合理的做法是 “走进式回测(walk-forward)”:假设你站在 2018 年末:只用 2014–2018 的数据来训练/选择因子、调参数然后用这套配置去跑 2019 年的回测然后时间滚动:用 2015–2019 的数据训练跑 2020 年这样做出来的 IC、策略收益,才更像现实中“你当时能看到的数据 + 你的决策”。如果:全样本一次性调出来的结果很美走进式(只用历史数据滚动)之后,表现缩水很多说明:你的方案对“未来未知数据”的泛化能力很一般,有过拟合风险。
4. 参数越多,越要警惕:复杂度 vs 样本量
常见的“过拟合信号”:
一个因子里塞了很多自由度:
各种窗口(3/5/7/10/20日)
各种权重(0.3、0.5、0.7 拼来拼去)
各种条件分支(如果 xx>yy 且 zz<ww 就…)
你为了追求更高的 IC,在无数组合中“刷”出最好的那个。
如果你:在几十个参数组合里挑了最优组合又只在一段 3–5 年的数据上验证基本可以认定是“向历史数据求教过多”,未来很容易打回原形。简单粗暴的防守策略:尽量控制每个因子的“自由参数”数量(能少就少)
每调一次参数,都要看它在新的时间段上是否仍然稳健优先选择“解释简单、经济含义清晰”的因子如果一个因子连自己都解释不清楚是啥逻辑,只是 IC 很好,那八成是过拟合。
5. IC 稳定性 vs 样本数量:别被几笔 IC 吓到
还有一种隐形的过拟合,是 样本太少:例如:你在一个很短的周期(半年、一年)上看 IC。因子刚好在那几个月表现超好。结果:Rank_IC_mean 可能有 0.1、0.2,t 统计量看起来也不低。但问题是 T 太小(比如只有 50 个样本点):统计不稳定,非常容易“运气好”。
简单原则:
做因子评估时,至少要有 2–3 年的日频样本(>500 期)
越长越好,至少涵盖几轮不同市场环境(牛、熊、震荡)
如果你的因子:
只在某一小段行情(比如 2020 年疫情行情)表现突出
其它年份表现一般甚至反向
那它很可能只是“特定行情因子”,未来能不能复制要打问号。
6. 多因子组合里的“过拟合”信号
当你开始做多因子加权时,还要小心一件事:
你是不是在用 IC、Sharpe 把权重“刷”出来了?
常见姿势:
拿 10 个因子
暴力搜索一堆权重组合(比如随机搜索/网格搜索)
挑出 Sharpe 最高的那组当“最终权重”
这在统计学上也属于高风险过拟合:你等于在历史上试了无数组合,总能刷出来一个“完美过去”的。
比较健康的做法:
因子权重有经济逻辑:
比如价值类、质量类、动量类各 1/3
或者用简单的机器学习/回归,但一定要:
做时间滚动验证
控制模型复杂度
观察测试集表现是否明显缩水
一旦你发现:
训练集上的组合 Sharpe 超级高
换时间段、换标的、换一点点参数之后掉得很厉害
那就得大胆承认:这套权重组合极大概率是“刷”出来的。
7. 一个给新手的“过拟合自查清单”
你可以用下面这张 checklist 自己审查因子:
只在一段历史上调参了吗?
是 → 高度怀疑过拟合
是否做了时间切割(训练/验证/测试)?
测试集表现是否明显比训练集差一大截?
是否在别的标的/行业/品种上验证过?
换一波股票、一批期货,IC 是否还能活着?
因子参数多不多?逻辑复杂到自己都解释不清楚没有?
很复杂、参数很多 → 风险很大
样本长度够不够?
只在一年、两年里调出漂亮结果 → 不可信
多因子权重是“刷”出来的还是有逻辑的?
只看哪个 Sharpe 高就选哪个 → 有刷榜嫌疑
只要你诚实地对这几个问题打勾,基本就能对“我这因子过拟合没”有一个比较清醒的判断。
最后一句话:IC、IC_IR、单调性、t 值 p 值 → 告诉你“在这段历史上”因子好不好。训练/验证/测试、跨市场验证、走进式回测 → 告诉你“未来大概率”还能不能行。过拟合最大的本质就是:你用太多自由度“迎合”了历史,忘记了自己真正要预测的是未来。做因子的时候,永远记住这句:宁可要一个逻辑清晰、在各段数据上“表现中等但稳定”的因子,也不要一个 IC 爆表但一换时间段就归零的玄学因子。
