密码登录
手机号
密码
先说结论:这篇研报让我觉得最爽的一点 就是它告诉我——你别老盯着那个总涨跌幅看,里面东西是混在一起的。 就像你喝一碗汤,觉得味道不对,不是因为汤不行,而是里面既有鸡肉又有姜片,你得分出来。这个“分”的动作,就是切割。 我以前做因子,就是傻乎乎地算个过去20天收益,跑出来IC时好时坏,我还以为是市场有病。现在看来,是我自己没把数据洗干净。 --- 我到底学到了啥(说人话版) 第一,涨跌幅可以拆成“好日子”和“坏日子” 不是按涨跌拆,而是按某种行为特征拆。比如大单多的日子和小单多的日子。 报告里那个理想反转因子,本质就是:大单多的那几天涨跌幅加起来,减去小单多的那几天涨跌幅加起来。...
PandaAI,让AI交易成为现实。 「AI+量化实战闭门分享」 【05.18/周一晚上8点闭门直播】 《好的交易数据怎么被AI真正用起来?》 🙋♂️分享嘉宾: 量化李不白 PandaAI创始人|全网20w粉量化科普博主 大盘手网·期货实盘大赛史上最年轻盘王 量化交易实战派,AI驱动交易探索者 吴振宇 奇货可查创始人 AIOPC实践者,10年+量化经验 持仓/成交量数据专家 直播回放已生成: 点击👉:[🔗观看完整回放](https://s06g2.xetslk.com/sl/w...
1.单agent框架搭建 根据这周的任务和教学视频的学习情况,本周准备先开始尝试把单agent框架跑通,也是让自己更快的了解整个工作流的搭建和模块功能; 就采用了比较熟悉的多因子截面策略开始尝试跑通整个工作流,给agent设置了提示词: 角色与目标 你是一名专业的量化研究员,专注于港股(HK)市场的多空截面选股策略。 核心目标:给定股票池,基于多因子模型识别并排序出最具投资价值的标的, 同时给出对冲空头标的,构建多空组合,实现市场中性收益。 市场 港股:股票代码以.HK结尾(例:007...
量化金融因子快速积累方法 对于量化从业者而言,快速、高效地积累优质因子,既能缩短策略研发周期,也能构建差异化竞争优势。不同于盲目堆砌因子,科学的积累方法需兼顾“快速获取”与“有效筛选”,实现从“数量积累”到“质量沉淀”的高效跃迁,以下是经过实战验证的量化金融因子快速积累路径。 一、筑牢基础:明确因子核心认知,避免无效积累 快速积累的前提是“方向正确”,若对因子的本质、分类与评价标准缺乏认知,盲目收集或构建因子,纯浪费算力 首先需明确核心前提:量化因子是能量化的、可解释的,且能稳定预测资产未来收益的资产特征,其核心价值在于“捕捉市场规律”,而非单纯的统计数据堆砌。 第一步,因子分类。 因子的...
</br <fontcolor="red"P值就是一件事是偶然发生的概率!</font </br  --- 今天我们把假设检验、显著性水平、P值、临界值、拒绝域这几个最容易混淆,但在量化研究里又必须掌握的统计概念,一次性讲透、讲明白。 “p值”具体代表什么含义? 是percent(百分比)? 是poss...
1.1搭建交易智能体的初衷与思路 作为刚接触量化和AI工具的小白,一直想拥有一个能自动分析行情、识别交易信号的小助手,不用每天对着K线手动研究; 希望借助PandaAI平台,把复杂的期货分析逻辑交给AI完成,自己只需要设置规则,就能实现自动化分析; 不想写复杂代码,只想通过简单拖拽节点、配置提示词,快速搭建属于自己的交易智能体,降低上手门槛; 然后进行了单智能体的初次尝试 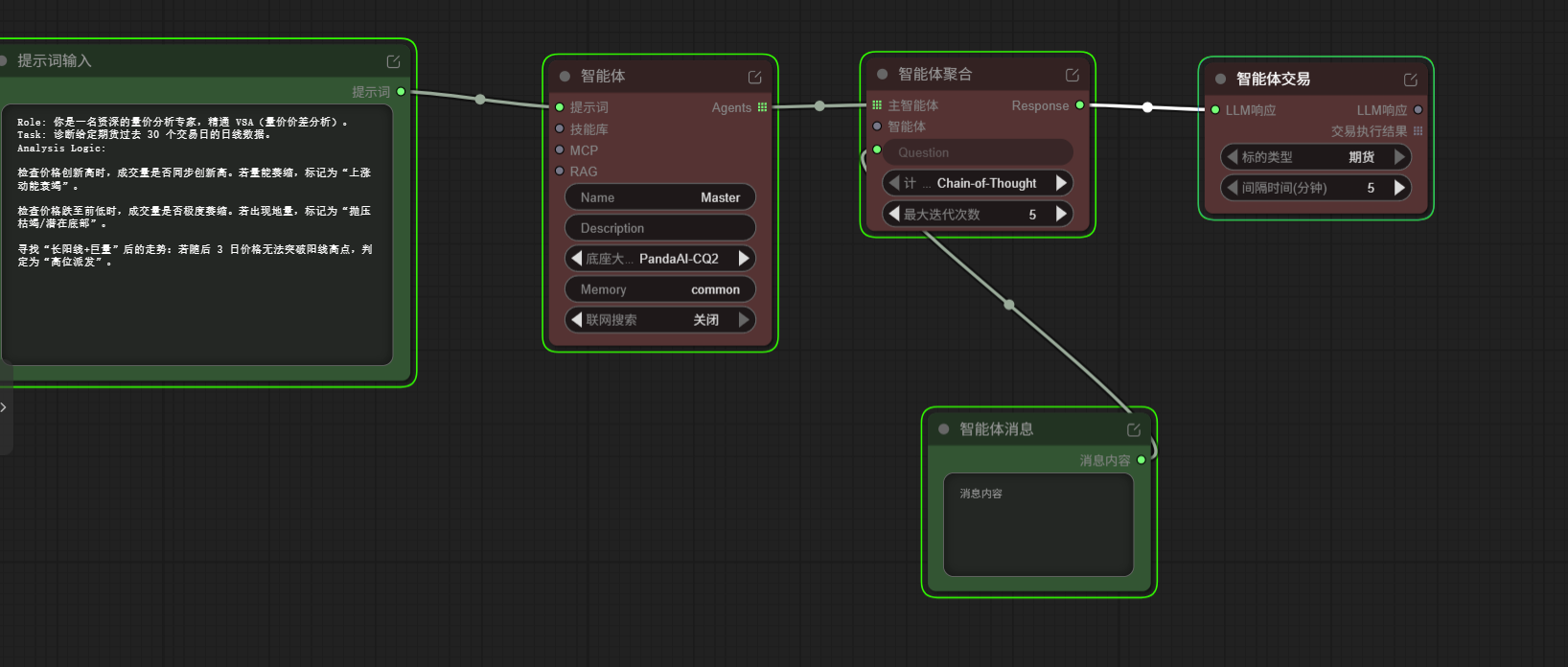 初次...
</br <fontcolor="red"统计学是收集、分析、表述和解释数据的科学。</font </br  量化交易的本质,就是用统计学的方法,从海量的历史交易数据(K线、成交量、财务数据、另类数据)中,找出那些长期稳定存在、且具有正期望收益的“统计规律”(因子),并利用这些规律进行交易获利。 下面我...
</br <fontcolor="red"当下借助大模型,正是学习量化投资的黄金时机,我们勇敢迈出第一步吧!</font </br  <fontcolor="brown"量化学习路线图</font 为了让刚入门的朋友清晰掌握量化学习的完整脉络、避免走弯路,特此整理量化入门学习路径全景总结。从零基础入...
PandaAI,让AI交易成为现实。 「全新AI智能体搭建功能上线」 在PandaAI社区,我们不炫算法,只拆解能落地的AI+量化实战。这一次,由PandaAI大模型团队工程师手把手带你,从“能聊天”到“能干活”,用Agent搭建真正帮你做投研分析的AI交易员。 【04.09/周四晚上8点闭门直播】 《手把手教你搭建,你的专属投资助手》 🙋♂️分享嘉宾:陈冠廷 PandaAI大模型团队工程师 LLM+量化交叉领域实践者 量化赛道的“工具控” 他说:代码不应该成为你和Alph...
</br <fontcolor="red"从扔硬币(伯努利)开始,扔多了变二项,无限扔变正态,标准化变Z,样本小了变t,平方了变卡方,相除了变F。</font </br 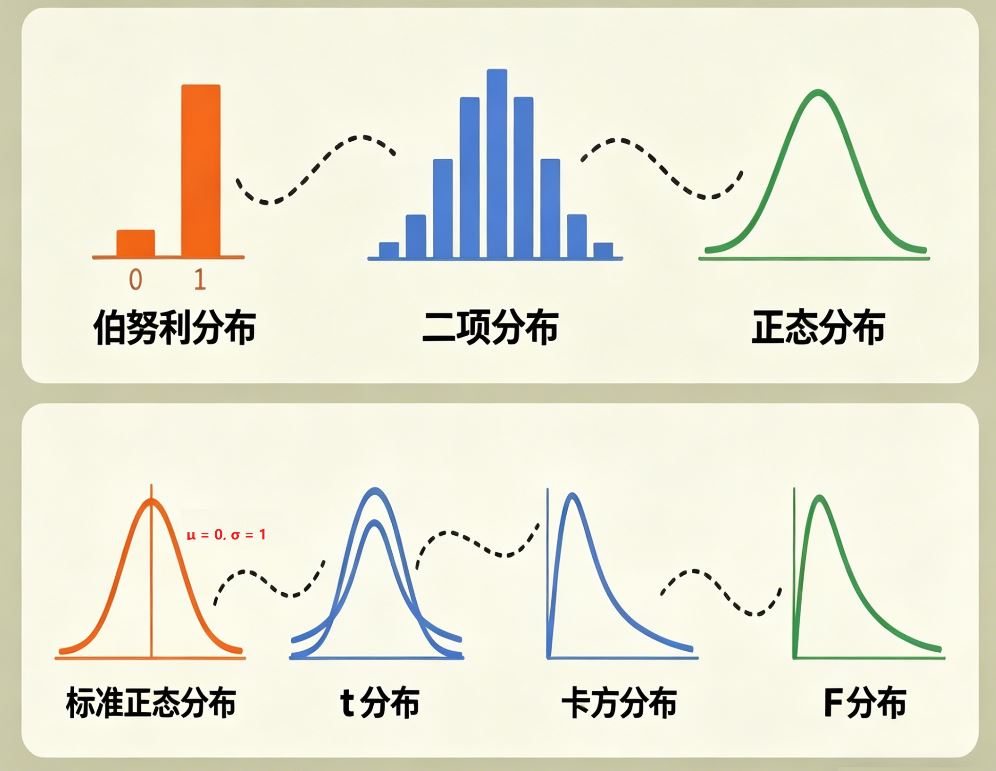 我刚初学概率分布时,都会觉得概念零散、难记、难理解,仿佛彼此毫无关联。实际上,伯努利分布、二项分布、正态分布、标准正态分布、t...
今天我们来探讨一个十分重要且应用广泛的统计学概念——置信区间。 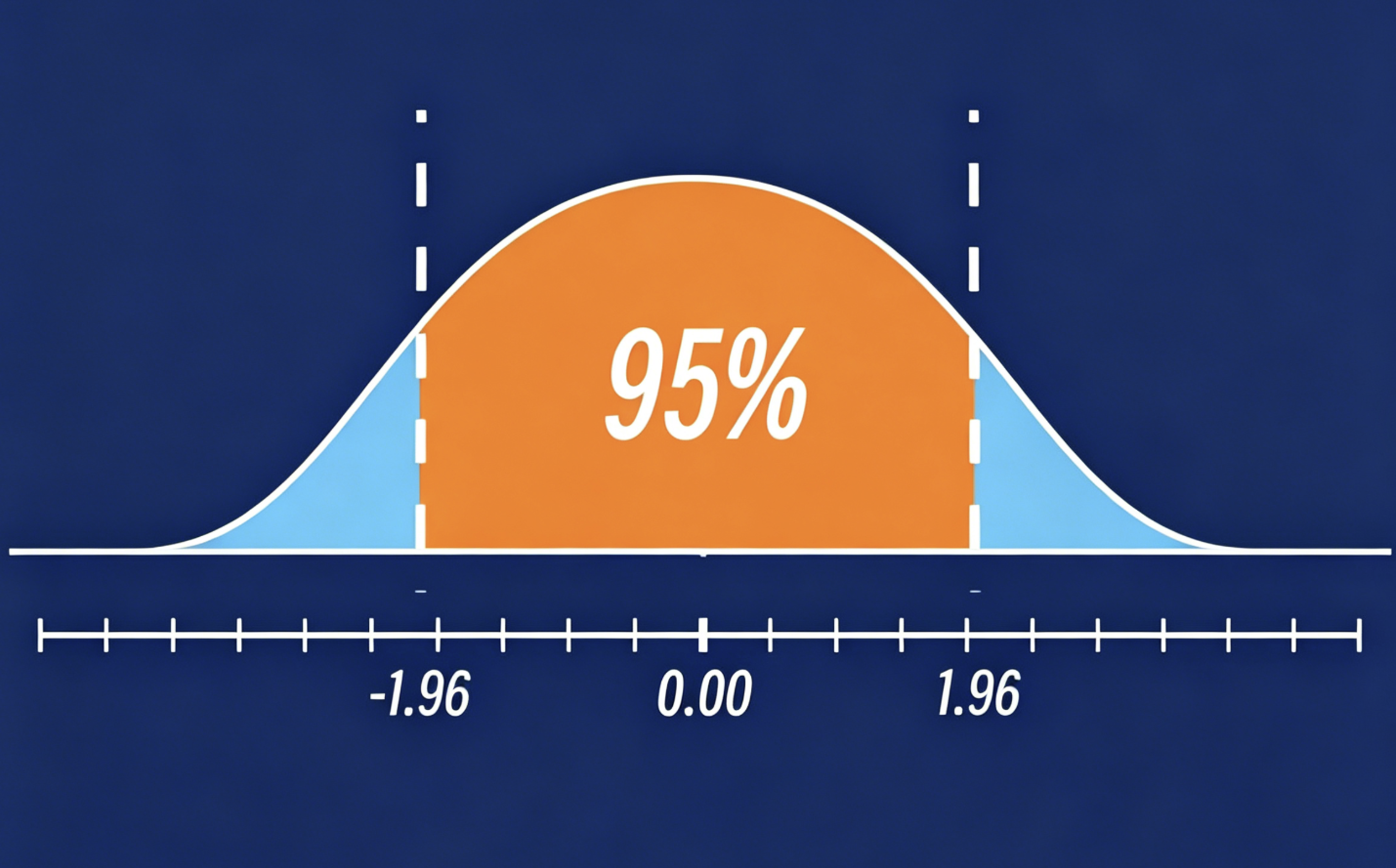 置信区间(confidenceinterval)是推断统计中参数估计的核心分支,是对“点估计”的补充与完善。以下是从定义、原理、分类到计算公式的完整总结,适配量化投资实战理解。 你或许在用户调研报告中见过这样的表述:“用户满意度平均得分为80,95...
4月26日📈从交易员数字分身,到基本面数据Skills化! PandaAI,让AI交易成为现实。 「AI实盘系列直播全新上线」 在PandaAI社区,我们不谈空泛概念,只拆解能落地的AI+量化实战。 这一次,由量化李不白发起,联手一线交易员与AI研究员,带你真正走进AI辅助交易的研究与实盘链路。 · 【两晚连播·扫码锁定】 🌙DAY1/4月26日20:00 《顶尖交易员如何打造自己的数字分身》 嘉宾:松鼠Quant、慕总、朱总(机构基金经理/CTA量化资管) 直播回放:[点击此🔗观...
一规则类策略与因子类策略的区别 1.1数据连续性不同 规则类策略规定了买卖点,因而是不二类型的,不连续,比较少能够借助统计理论进行统计分析和检验; 因子类策略没有规定买卖点,因此是不二类型的,是连续的,能够借助统计理论进行统计分析和检验,从而可以更科学的进行交易决策;
</br <fontcolor="red"多因子分析这套逻辑本质上就是把我们本能的判断方式,变成了可量化、可检验、可复现的系统方法。</font </br  --- 今天用一个大家每天都在接触的领域——食品营养学——来帮大家彻底搞懂多因子投资框架。 先问大家一个问题:你知道你每天吃的食物,对你身体到底有什么影响吗? 大多数人的回答是:苹果好,多吃水果有益健康。 但营养学家会问:苹果里的哪种成分,在什么剂量下,对哪类人群,能产生多大程度的健...
不知道为啥老是提示这个错误。实在是不知道怎么解决。有大哥知道吗。万分感谢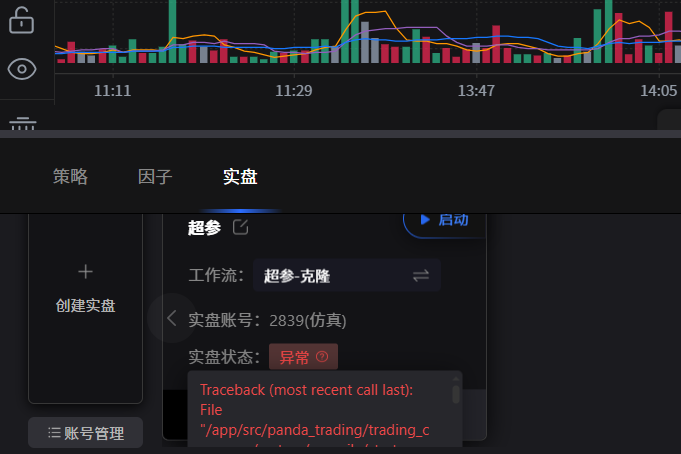 Traceback(mostrecentcalllast):File"/app/src/panda_trading/trading_common/system/compile/strategy_utils.py",line69,instrategy_...
在PandaAI社区,我们不炫算法,只拆解能落地的实战经验。这一次,由PandaAI的社区作者【我是宽客】,拥有10年金融+IT复合背景的工程师,手把手带你走一遍“零基础入门量化”的真实路径,从多因子模型到Python策略落地,全程无保留分享。 【05.08/周五晚上8点闭门直播】 《如何零基础入门量化——我的真实转型之路》 🙋♂️分享嘉宾:卡卡罗特|公募基金后端工程师 PandaAI社区作者【我是宽容】 多因子模型实战派,熟悉完整分析框架 10年金融+IT背景,持量化金融分析师等多项证...
💬在PandaAI社区,我们深入探索AI与交易的融合前沿,深度对话中连接业内人士,与思考同频的人并肩前行,让前沿认知转化为你的决策优势。 🐼5月高价值社区活动如下: 05.08/周五-线上闭门分享 《如何零基础入门量化》 @卡卡罗特 📈📈05.10/周日 《第三期多因子线上//课》 @量化李不白 📈05.14/周四-线下Workshop 《手搓你的第一个因子》 杭州·浙江财经大学@量化李不白 📈05.18/周一-线上闭门分享 《好的交易数据怎么被AI真正用起来》 @奇...

