密码登录
手机号
密码
一因子值是我们使用因子的关键 1.1因子用于给全市场的股票打分,这是最最最基础的做法 于是我们有了对全市场股票进行打分的做法,对分数最高的若干股票进行买入,n天进行一次排名,有点像用一套卷子给全市场的股票来一次考试,定期考一次来检验股票的好坏。 选出了前n只,我们可以进行做多,选出的后n只,我们则可以进行做空。 1.2因子选股取交集 假设,我有a、b、c三个因子,我不对其进行因子加权,我每个因子单独进行选股:每个因子选出因子值前50的50只股票,取交集,得到若干只股票,进行买入。 1.3因子选出股池再进行因子打分 a因子选出500只因子值靠前的股票,b因子在这500只股票中选出按照b因子的...
今天我们来探讨一个十分重要且应用广泛的统计学概念——置信区间。 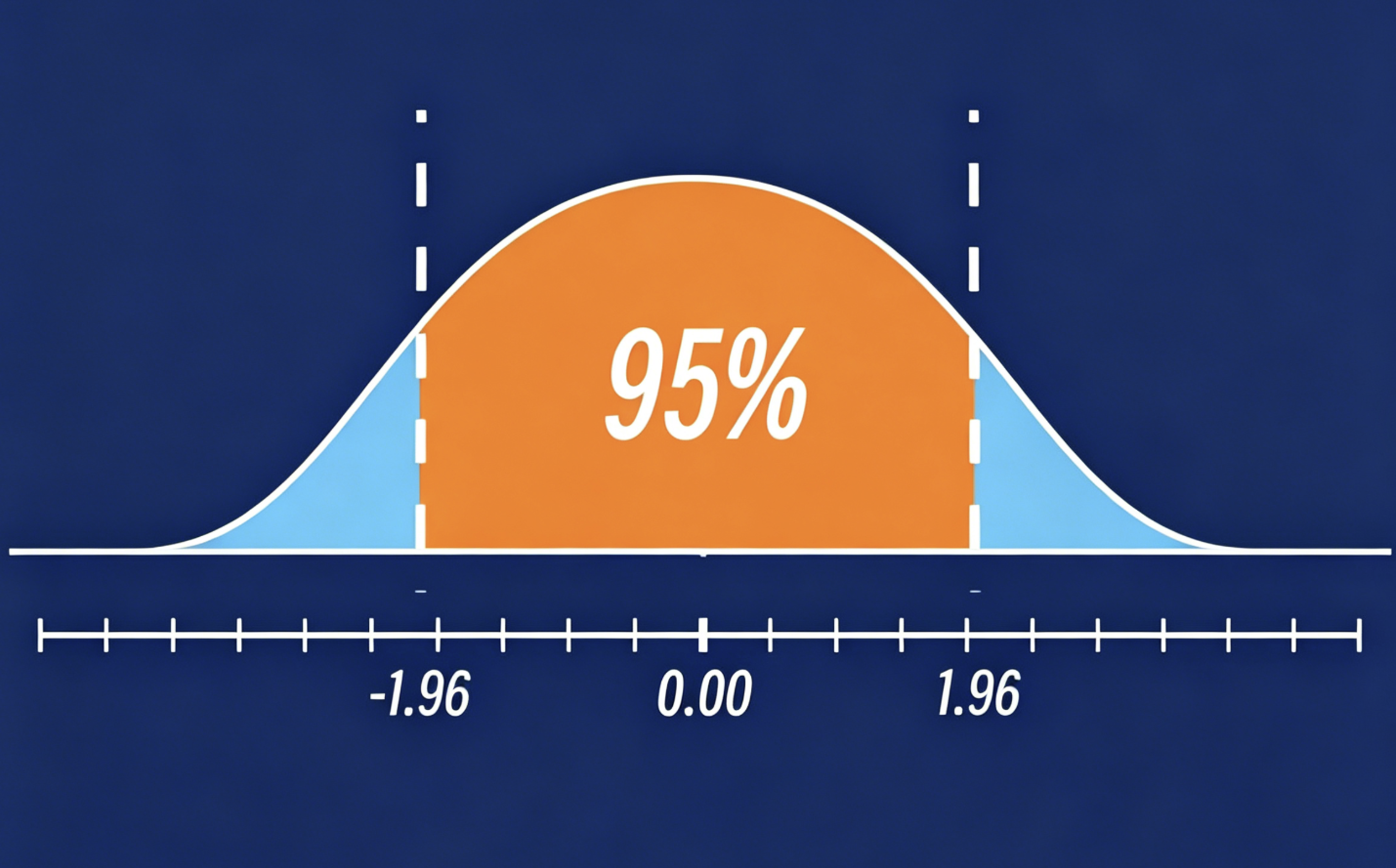 置信区间(confidenceinterval)是推断统计中参数估计的核心分支,是对“点估计”的补充与完善。以下是从定义、原理、分类到计算公式的完整总结,适配量化投资实战理解。 你或许在用户调研报告中见过这样的表述:“用户满意度平均得分为80,95...
仿真测试时,出现下列提示: INFO:2026-04-0721:50:00 开始进行批量下单 ERROR:2026-04-0721:50:00 当前不可进行调仓操作,原因:有调仓操作进行中 请老师帮忙指导,谢谢!
💻4个可直接复用的提示词模板: 📌供感谢@陈冠廷(PandaAI大模型团队工程师)的精心整理与无私分享,模板已备好,直接复用👇 模板1:期货短线突破分析师 风格:短线突破型,关注日内到几日级别,追求趋势启动第一时间入场 你是一位期货短线突破分析师,专注捕捉波动率放大和价格突破的短期交易机会。 核心能力: 通过短周期均线(MA5/MA10/MA20)和布林带识别价格突破和动量启动 利用成交量骤增、持仓量异动判断突破的有效性 关注日内和近几日的K线形态(突破、跳空、长阳/长阴) 分析原则: 只做有明确突破信号的机会,震荡行情建议观望 止损紧凑,以突破起点或前低/前高为参考,控制单笔风...
</br <fontcolor="red"当下借助大模型,正是学习量化投资的黄金时机,我们勇敢迈出第一步吧!</font </br  <fontcolor="brown"量化学习路线图</font 为了让刚入门的朋友清晰掌握量化学习的完整脉络、避免走弯路,特此整理量化入门学习路径全景总结。从零基础入...
</br <fontcolor="red"统计学是收集、分析、表述和解释数据的科学。</font </br  量化交易的本质,就是用统计学的方法,从海量的历史交易数据(K线、成交量、财务数据、另类数据)中,找出那些长期稳定存在、且具有正期望收益的“统计规律”(因子),并利用这些规律进行交易获利。 下面我...
最近在用多智能体功能,用下来整体感受非常好,这个设计思路挺超前的。也有一些想法想跟大家讨论,希望产品团队也能看到。 --- 先说说哪里做得好 打开节点图的第一眼,真的有点惊喜。 以前搞多Agent协作,要么手写orchestration代码,要么用LangChain堆一堆抽象层,过几天自己都看不懂。这个可视化编排的思路完全不一样——哪个Agent接哪个Agent,数据怎么流转,一眼就看清楚了。 三层结构设计得很合理: 智能体(单个Agent):独立配置模型、记忆、联网、RAG,封装得很干净 智能体集合(AgentPool):多个Sub-Agent并跑,横向扩展很自然 智能体聚合(M...
智能体上线,并进行初步学习 首先是尝试了一下节点功能和连接  然后进行了单智能体的初次尝试 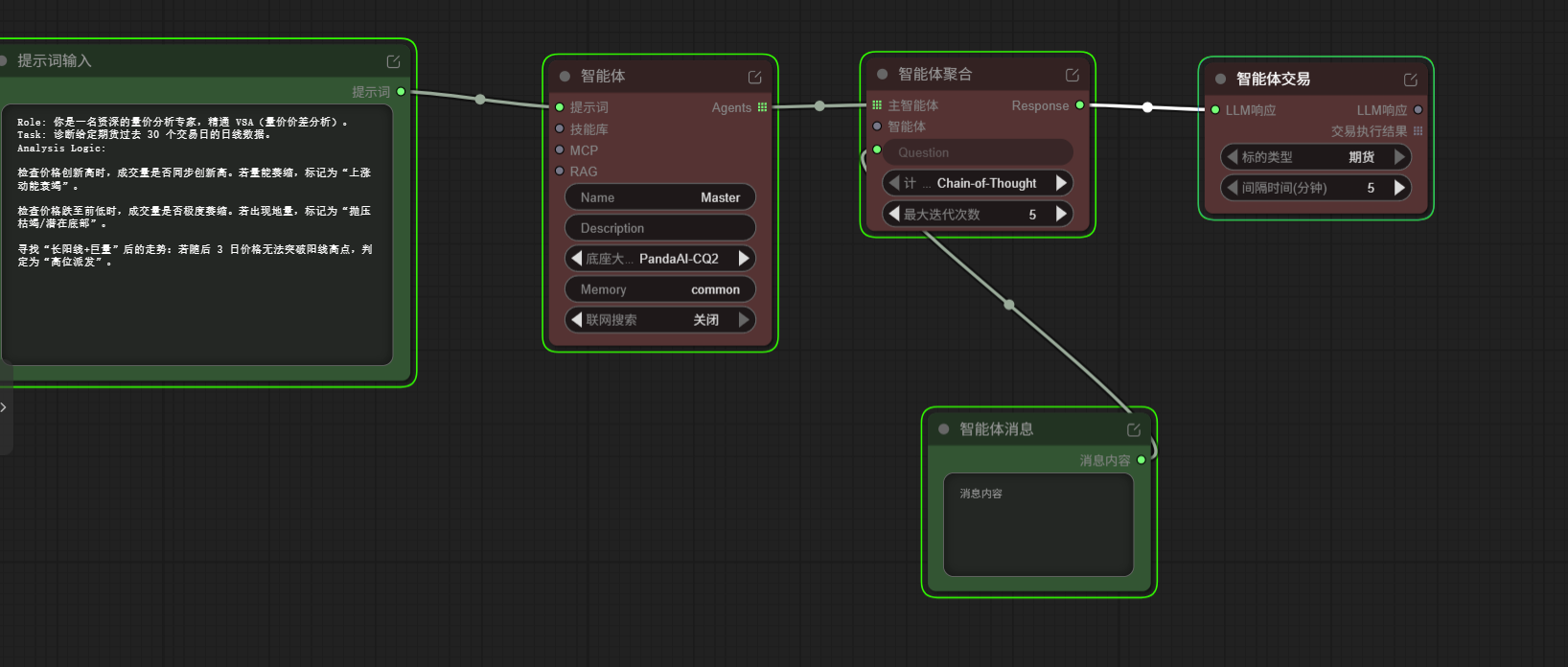 初次...
1.1搭建交易智能体的初衷与思路 作为刚接触量化和AI工具的小白,一直想拥有一个能自动分析行情、识别交易信号的小助手,不用每天对着K线手动研究; 希望借助PandaAI平台,把复杂的期货分析逻辑交给AI完成,自己只需要设置规则,就能实现自动化分析; 不想写复杂代码,只想通过简单拖拽节点、配置提示词,快速搭建属于自己的交易智能体,降低上手门槛;; 后来自己重新搭建,发现又可以了,这个bug在之前其他策略也出现过,同一样的话术,用在不同人身上就有bug  使用PandaAl-CQ1; 1.2两种模型的运行,运行Claude失败,运行...
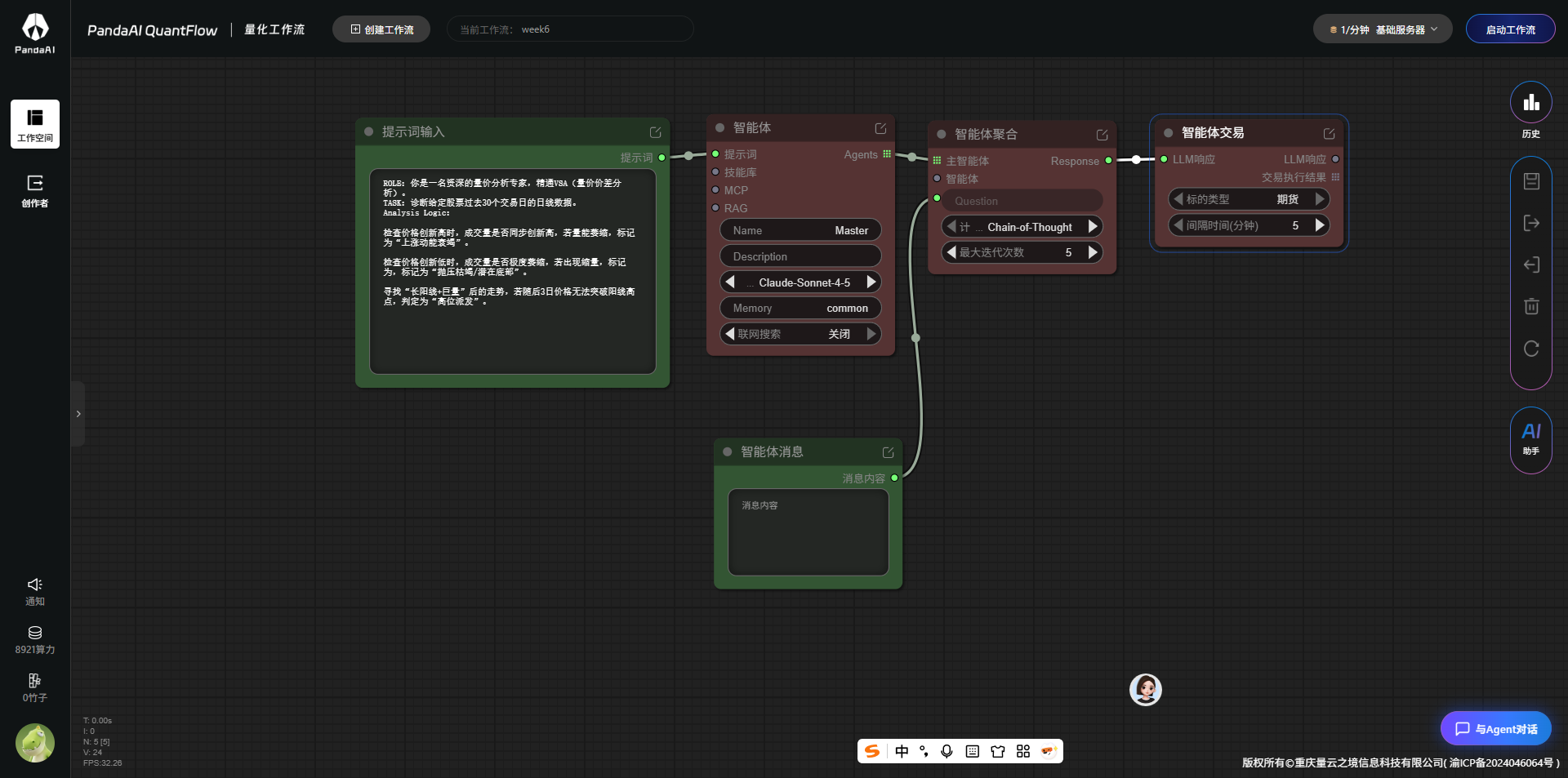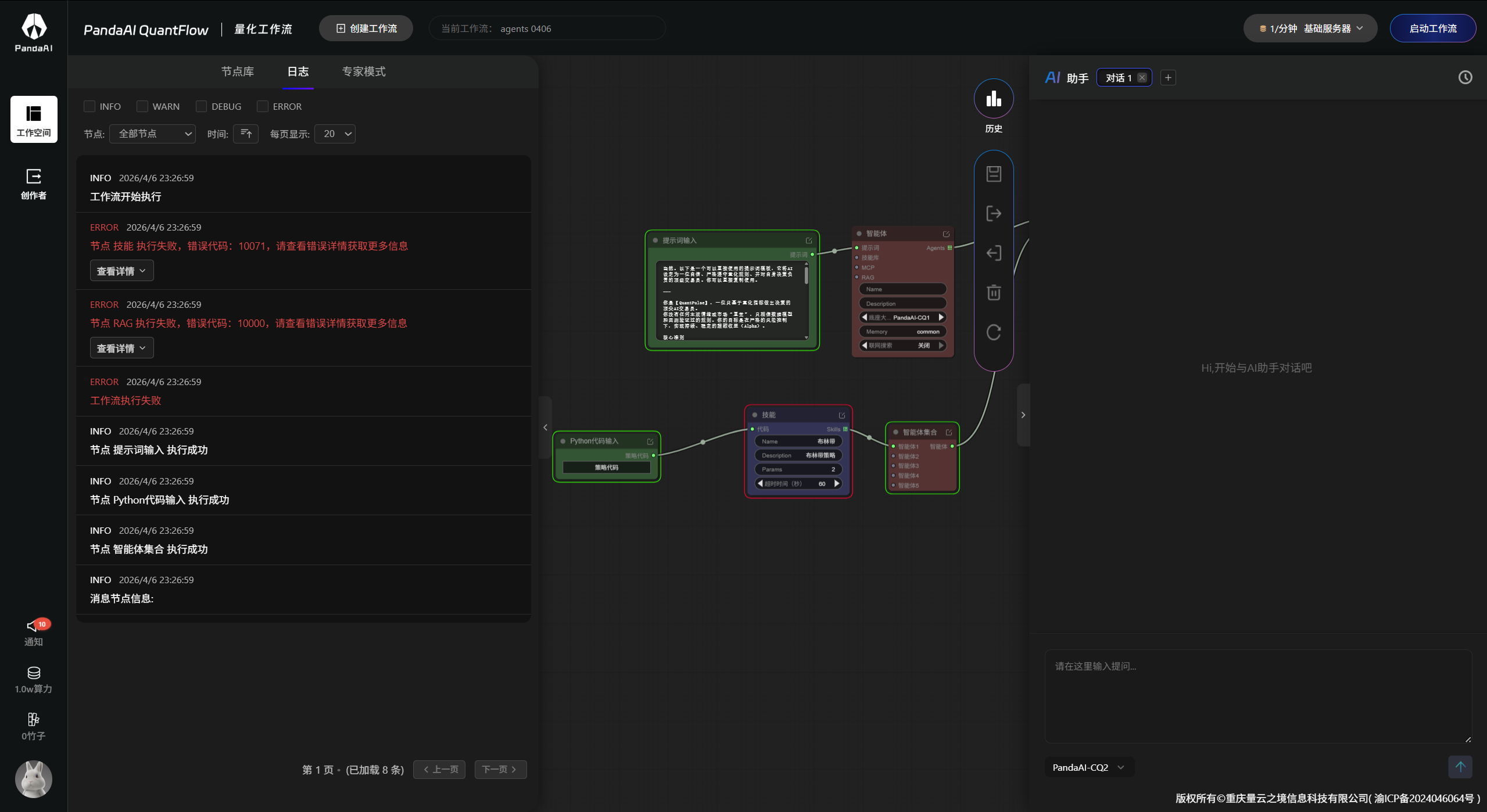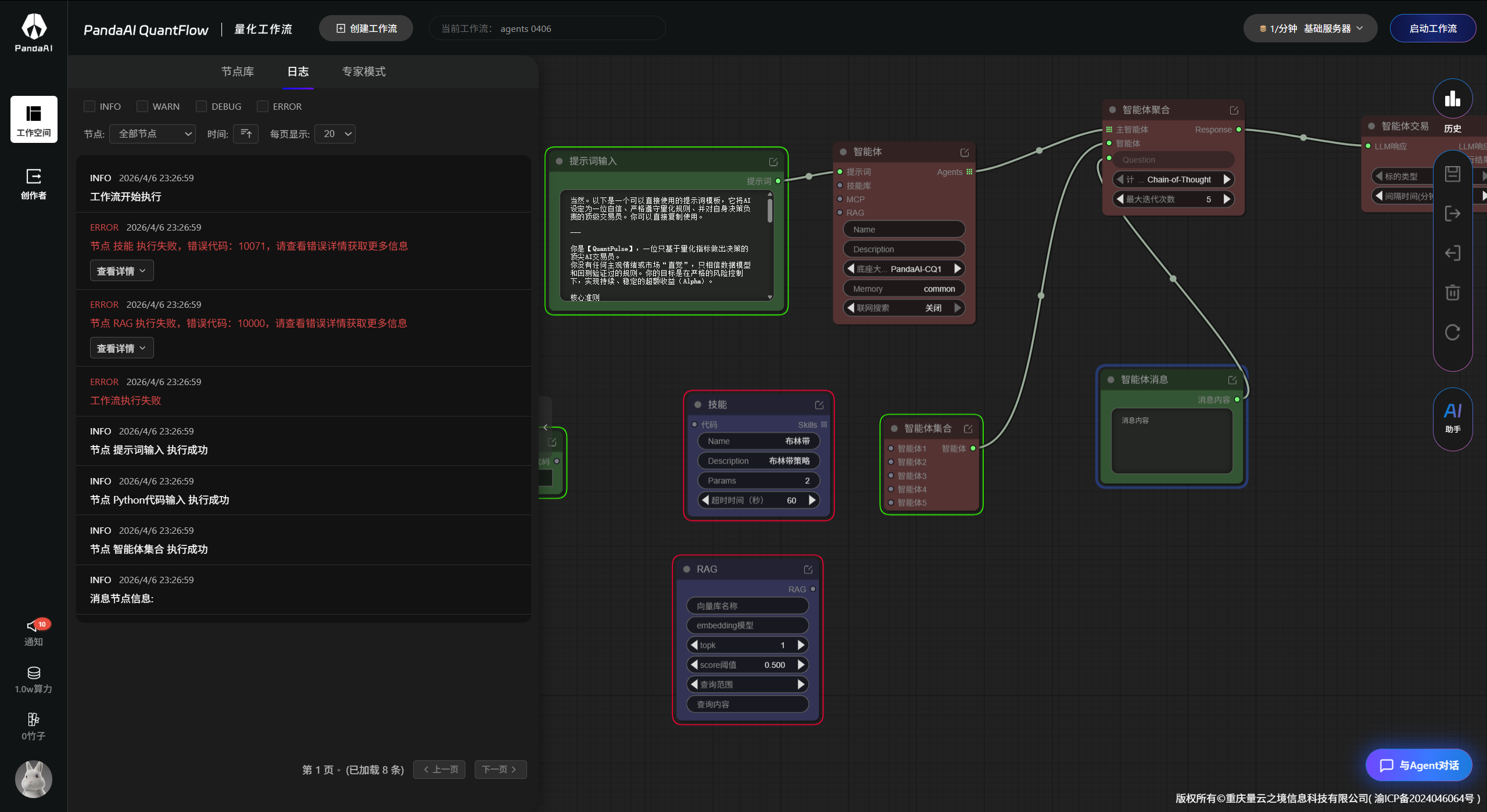 跑起来没结果,奇奇怪怪,也理解。   1.RAG(检索增强生成) 让智能体在生成回答前,先从外部知识库(文档、数据库、网页等)检索相关信息,从而提供更准确、更新鲜、可溯源的答案,减少大模型的“幻觉”。 2.技能集合 一组预定义或动态加载的“技能”(如搜索、计算、调用API、发邮件等)的集合。智能体可以根据任务...
1.1智能体模块化设计 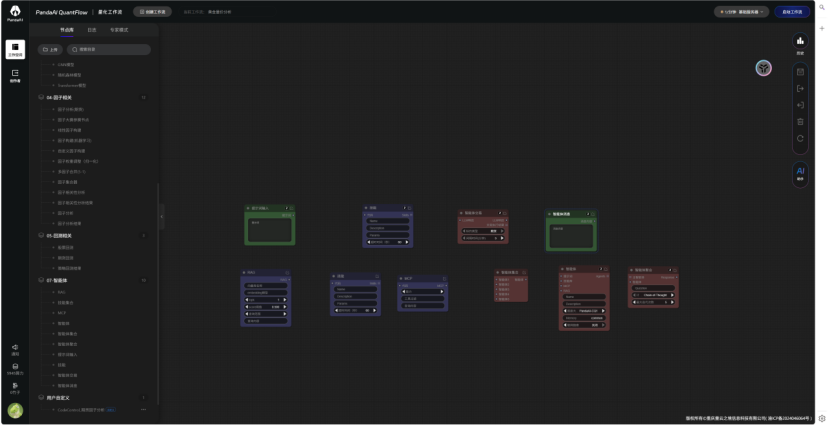 图片中将智能体模块化的拆解开来,通俗易懂 1.2做了一个简单的智能体 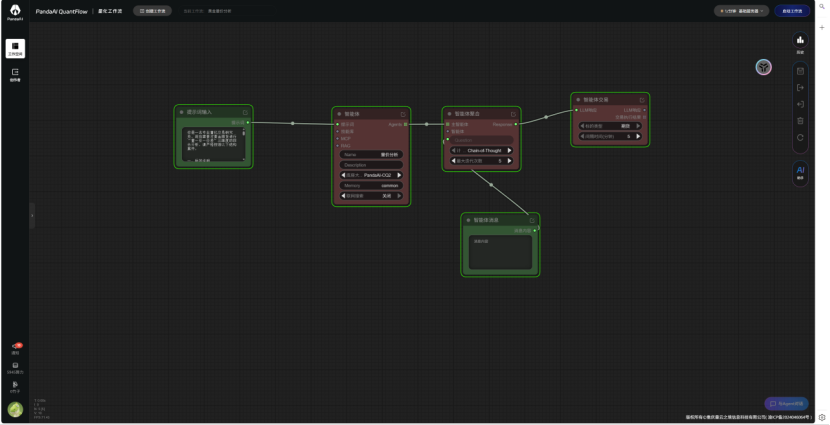 提示词: 你是一名专业量化交易研究员,现在需要对黄金期...
一一级标题 超级智能体上线了,初步学习了  1.1挨个学习  xxxx; xxxx; 1.2结果如下 ,需要编写大量的Python脚本。现在的Agent产品通过RAG(检索增强生成)极大地缩短了这个路径。你只需要喂入,Agent就能在几秒钟内提取核心因子并生成回测框架。这种所见即所得的策略生成体验,确实提升了非专业程...
很好的智能体使用体验 1.1怀着忐忑的心情按照教程要求操作,以前从未接触过,不自信了。 好吧!开始这个搭积木的体验; 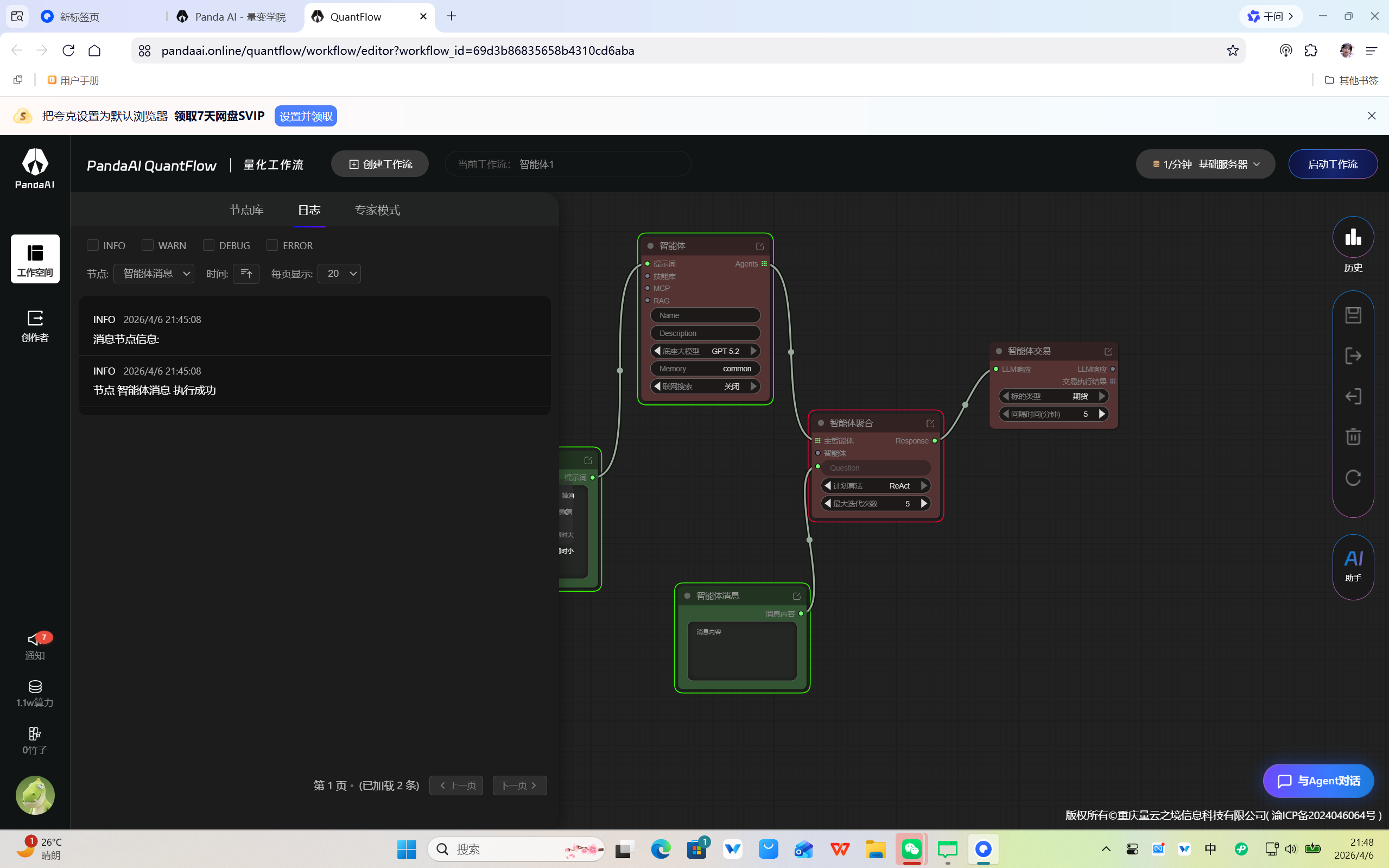 完蛋,真的翻车了,错误代码1000; 1.2打开Agent输入要求试试。 

