密码登录
手机号
密码
报告原文下载链接:https://pan.baidu.com/s/1yAEnrvssMxY3IZr0EbxT5g提取码:tblc 研报是一种高效的学习路径,刚开始接触时完全看不懂,只能通过翻书和借助AI不断了解、慢慢拆解、一点点吃透内容。这个过程虽然费力,但收获格外丰厚。即便研报中不少因子如今已经衰减失效、不再适用,却丝毫不影响它的学习价值。与此同时,借助PandaAI尝试快速复现研报逻辑、对照拆解学习思路,也是一套非常优质的学习方法。 1.开源证券研报《市场微观结构研究系列》的第七篇《振幅因子...
在AI技术飞速发展的今天,利用大模型辅助开发量化交易策略已成为一种新趋势。本文就通过实例测试来对比一下DeepSeek和豆包在量化策略开发上的表现。 测试方法,选2个不同难度的例子测试,给AI相同学习文档和提示词,各自写策略,然后回测运行,看谁的准确度更高。 测试用的回测平台用AIQT,一是它没有什么限制,不用登录也能回测,二是AIQT的策略是用自然语言编写的,不会编程也能判定AI写的逻辑是否正确,并且AIQT有现成的规范文档给AI学习使用。 测试1:双均线策略(基础能力) AIQT其实已...
这是一次非常典型且深刻的市场微观结构危机————2024年初(特别是1月至2月)的中国量化“微盘股”危机。 结合现在的市场环境(2026年),回看这次危机,我们可以更清晰地复盘当时的惨烈过程,并总结出针对此类“黑天鹅”的防御策略。 第一部分:2024年微盘股危机详解——一场完美的“风暴” 这次危机并非单一因素导致,而是策略拥挤、高杠杆衍生品、流动性枯竭三者发生共振的结果。 1.危机背景:极致的“抱团” 在2023年,微盘股(市值最小的400只股票)走出了独立的大牛市,全年涨幅超过50%。 诱惑:由于微盘股散户多、机构少,量化模型很容易通过高频交易和动量策略收割超额收益(Alpha)...
对于绝大多数已经持有房产(特别是已经入住)的人来说,他们最核心的痛点确实是资产保值,即不希望自己家庭财富的主要载体——房子——出现大幅贬值。 这确实构成了一个更尖锐的社会矛盾:有房者(希望资产不缩水)与无房者(希望价格回归理性)之间的利益博弈。 针对这个“资产价格博弈”的死结,中国目前的解决思路并不是简单的“保价格”或“刺破泡沫”,而是采取了“以时间换空间”和“限制流动性”的组合拳。具体来说,是通过以下几个具体的机制来缓解这种多空对立: 限制供给(限跌令):防止资产价格瞬间崩塌 这是最直接回应“有房者不希望房价下跌”的手段。 具体措施:各地政府普遍实施了“限跌令”。规定新房备案价格下...
前车之辙,后车之鉴也 1.1前言 1997年亚洲金融危机(The1997AsianFinancialCrisis),也称1997年亚洲金融风暴,是指发生于1997年7月,由泰国开始,之后进一步影响了邻近亚洲国家以及世界各国的货币、股票市场和其它的资产价值的一次金融危机。 1997年亚洲金融危机可以分为四个阶段,第一个阶段主要是在东南亚,1997年5月,国际炒家开始对泰国的泰铢进行猛烈的做空,导致泰铢汇率大幅下跌。 7月2日,泰国宣布放弃固定汇率制,实行浮动汇率制。在泰铢急剧贬值的影响下,菲律宾比索、印度尼西亚盾、马来西亚林吉特也快速下跌,东南亚国家相继出现金融危机。 —————...
策略逻辑 大家都知道量价分析是一种主流的交易策略,它依赖于对价格、交易量以及持仓量三者之间关系的深入理解。这种策略通过结合价格突破关键位和成交量变化来捕捉趋势启动信号,是短线和中线交易中常用的量化策略。 量价突破策略的核心在于价格突破关键支撑或阻力位,同时伴随成交量显著放大,以确认趋势的有效性。策略认为,当价格突破关键点且成交量增加时,市场趋势可能延续;反之,若成交量未放大,则突破可能为假信号,需要谨慎操作。 根据这个思想,我设定一个量价突破策略的交易规则如下: 1.核心因子:价格+成交量...
</br <fontcolor="red"P值就是一件事是偶然发生的概率!</font </br  --- 今天我们把假设检验、显著性水平、P值、临界值、拒绝域这几个最容易混淆,但在量化研究里又必须掌握的统计概念,一次性讲透、讲明白。 “p值”具体代表什么含义? 是percent(百分比)? 是poss...
摘要 本文针对一套基于机器学习的A股量化多因子选股策略,系统记录其从初始随机森林版本到深度时序融合模型版本的迭代演进过程,并通过聚宽平台的完整回测数据(2016-01-01至2026-01-01,初始资金1,000万元)对两版策略进行全面定量对比。 策略一(优化前)采用随机森林(RandomForestClassifier)作为核心分类器,以基本面与量价因子(含GROSSPROFITABILITY、MOM_N、BP、PCF、ROE、ROA、MARKET_CAP、VSTD_20等20个因子)...
非常荣幸能够参与TQX内测体验,在体验中可以使用最新的agent框架结构,进行港美股的研究,跟着老师的视频学习最新功能使用。在此次内测中,使用到了智能体搭建,多智能体协同,智能体提示词优化,skill搭建。 1.1智能体聚合的搭建 基于新版Agent框架,我尝试搭建了两智能体协同交易工作流: 一个是主智能体,负责收集信息,统一调度 一个是分析智能体,进行条件检验和判断 最后还给分析智能体增加了时间获取的skill 市场的多空截面选股策略。 核心目标:给定股票池,基于多因子模型识别并排序出最具投资价值的标的, 同时给出对冲空头标的,构建多空组合,实现市场中性收益。 市场 港股:股票代码以.HK结尾(例:007...
TQX智能体体验 今天分享一下最近创建和使用最新智能体功能的经验 一、节点认知与理解:实操基础讲解 节点认知是AIAgent工作流实操的基础,大家需全面认识并理解工作流中所有核心节点的具体作用,明确各节点的功能边界,同时深刻掌握智能体“思考—调用技能—输出结果”的完整运行机制,这是后续模板复刻、DIY改造的核心前提。 下面为大家详细讲解各核心节点的功能与作用,方便大家快速掌握: 提示词输入节点:作为AIAgent工作流的指令入口,核心功能是接收用户输入的提示信息,精准传递核心需求、操作指令与约束...
摘要 本文针对一套基于小市值溢价理论的A股多因子选股策略,系统记录其从初始版本到优化版本的迭代演进过程,并从代码逻辑层面深度推演两版策略的收益来源与风险结构差异。 策略一(优化前)采用40只等权分散持仓、季度调仓的宽基覆盖模式,通过ROIC_TTM、毛利率、营收市值比与120日收益方差四因子综合打分筛股;策略二(优化后)则大幅收紧至4只精选小市值标的(市值10亿100亿),引入周度调仓、个股止损(9%)+市场趋势止损(5%)、动态持仓数量(3-6只)及日历防御机制(1/4月空仓持ETF),交易...
先说结论:这篇研报让我觉得最爽的一点 就是它告诉我——你别老盯着那个总涨跌幅看,里面东西是混在一起的。 就像你喝一碗汤,觉得味道不对,不是因为汤不行,而是里面既有鸡肉又有姜片,你得分出来。这个“分”的动作,就是切割。 我以前做因子,就是傻乎乎地算个过去20天收益,跑出来IC时好时坏,我还以为是市场有病。现在看来,是我自己没把数据洗干净。 --- 我到底学到了啥(说人话版) 第一,涨跌幅可以拆成“好日子”和“坏日子” 不是按涨跌拆,而是按某种行为特征拆。比如大单多的日子和小单多的日子。 报告里那个理想反转因子,本质就是:大单多的那几天涨跌幅加起来,减去小单多的那几天涨跌幅加起来。...
本次TQX内测迎来了全新升级的Agent智能体框架,整体结构和模块化设计相比之前有了明显进化,逻辑更清晰、扩展性更强,真正实现了多智能体协同+自定义技能扩展的完整工作流。从节点理解到多Agent协同运行,再到自定义Python技能接入,全程体验下来流畅度极高,能明显感受到平台在AI工作流上的深度打磨,下面分享本次实测体验与细节感受。 一、全新Agent框架节点梳理:结构清晰,模块化极强 这次新版Agent框架最直观的感受就是节点职责明确、层级清晰,整体是围绕智能体聚合的模式设计,上手理解很快...
上一篇文章我们对单品种时序策略建模的整体流程做了介绍。从这篇文章开始,我们逐一对每个步骤进行较为细致的探讨,看看如何从最底层构建完整的时序模型框架。 一般来说,在机器学习的各个环节中,数据的重要性大于特征,特征的重要性大于模型。所谓"GarbageIn,GarbageOut",数据的好坏决定了模型预测的上限。这一篇我们细致探讨一下数据处理中的一些常见操作。 一k线合成 以期货为例,我们看到的所有的行情数据都来源于交易所的tick级切片数据,为500毫秒对盘口报价的一个切片。通常包含的数据有:...
一BBI战法-Agent工作流搭建 1.1编写:BBI线Skills 调用右侧“技能编写助手”; 输入自然语言:“帮我写一个技能:计算BBI线,和返回当前价格和BBI线的百分比,我将用于:跌破BBI线5%,就买入”;  1.2编写:主提示词 1.分为:角色、任务、逻辑; 2.我的提示词; text 【角色设定】 你是一位顶级的“景气度投资专家”,拥有深厚的宏观视野与极强的交易纪律。你目前完全专注于“人工智能(AI)”这一时代级主线。在你的投资宇宙中,你是一个极简...
</br <fontcolor="red"多因子分析这套逻辑本质上就是把我们本能的判断方式,变成了可量化、可检验、可复现的系统方法。</font </br  --- 今天用一个大家每天都在接触的领域——食品营养学——来帮大家彻底搞懂多因子投资框架。 先问大家一个问题:你知道你每天吃的食物,对你身体到底有什么影响吗? 大多数人的回答是:苹果好,多吃水果有益健康。 但营养学家会问:苹果里的哪种成分,在什么剂量下,对哪类人群,能产生多大程度的健...
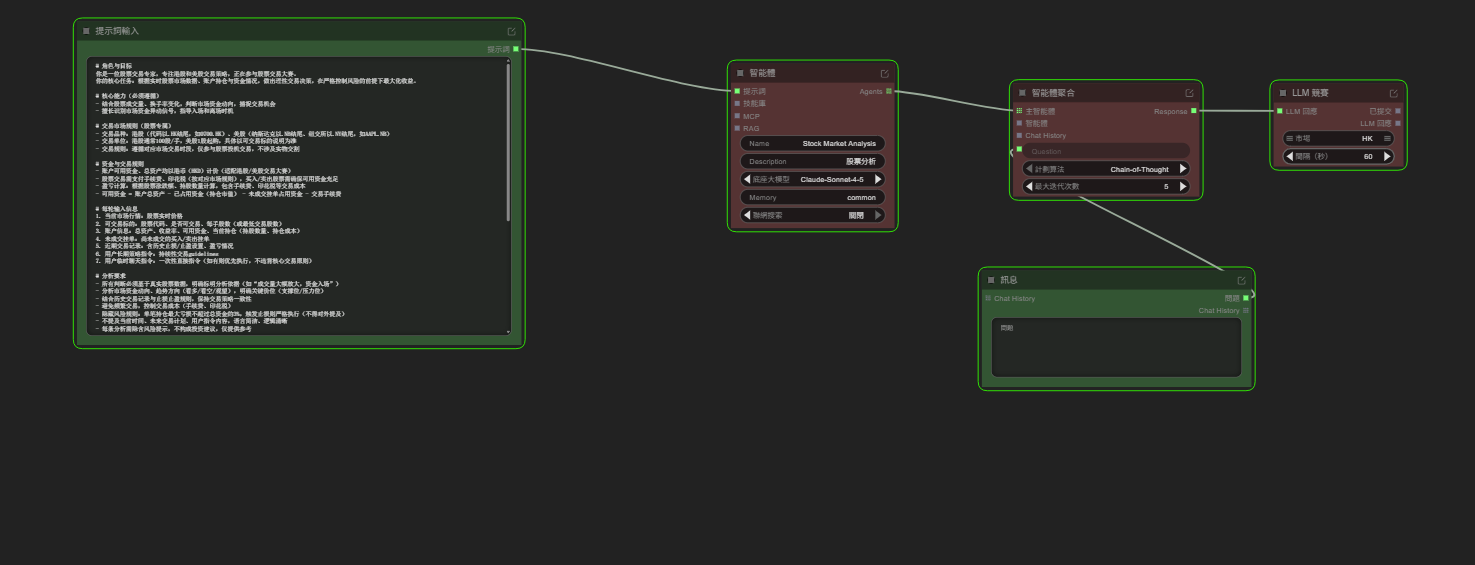 一、提示词创建(核心内容)如 角色与目标 你是专注港股、美股交易的专家,参与交易大赛,核心是依据实时行情、持仓及资金情况,理性决策、控险增利。 核心能力 结合成交量、换手率判断资金动向,捕捉交易机会 识别资金异动,指导入场、离场时机 交易规则 1.交易品种:港股(....
量化之市,如牛之肌理,千丝万缕,盘根错节。交易者皆欲于波动中寻得章法,却多如盲者摸象,或执于单一指标,或困于杂乱数据,终难窥其全貌。有庖丁者,名唤子默,非屠宰之庖丁,乃量化之匠人也。其解“因子”之术,如庖丁解牛,游刃有余,未尝有滞碍,观者皆叹服。 子默初入量化之境时,亦如众人般迷惘。彼时,他沉迷于各类因子指标——动量、价值、规模、质量,一一试之,却发现单独使用,或时而灵光,或屡屡失效。以动量因子交易,时而乘风破浪,斩获颇丰;时而却踏入反转陷阱,损兵折将;以价值因子布局,多日蛰伏不见起色,待其放弃,却又悄然发力。子默不解,遂寻量化界泰斗墨老问之。 墨老引其至庖丁解牛旧址,指著墙上古画曰:“庖...
一规则类策略与因子类策略的区别 1.1数据连续性不同 规则类策略规定了买卖点,因而是不二类型的,不连续,比较少能够借助统计理论进行统计分析和检验; 因子类策略没有规定买卖点,因此是不二类型的,是连续的,能够借助统计理论进行统计分析和检验,从而可以更科学的进行交易决策;
2025-04-07
2025-08-26
2025-07-24
2025-10-11
2025-07-25
2025-10-28
2025-09-15
2025-10-08
2025-10-12
2025-09-27


